迭代器(Iterator):
能够被 next()函数调用并不断返回下一个值,直到抛出 StopIteration 异常的,就是迭代器对象。
可迭代对象(Iterable):
可迭代对象能够被 for 循环遍历,可迭代对象都有迭代器,可以通过 iter 获取可迭代对象的迭代器,并通过 next()函数取出迭代器的值。
可以通过 from collections import Iterable,Iterator导入可迭代对象类和迭代器类,来判断对象是否迭代器,或者可迭代对象。
生成器(Generator):
生成器是特殊的迭代器
创建生成器的方法:
- 通过类似列表生成器的语法: (i for i range(100)),这样可以创建一个值为 0~99的生成器,并可以通过不断的迭代取出每一个值
- 通过类似函数的语法,使用 yield 返回值,就是一个生成器函数,语法如下:
def mygenerator():
a = 0
b = 1
while True:
a, b = b, a+b
yield a
生成器的操作:
- 使用 next()可以取出生成器的元素
- 使用 for 循环可以遍历输出生成器的每个元素
- 使用 list()可以将生成器转换成列表
- 使用 send()唤醒生成器,示例:
def gen():
i = 0
while i < 5:
temp = yield i
print(temp)
i += 1
# send 的使用:↓
In [43]: f = gen()
In [44]: next(f)
Out[44]: 0
In [45]: f.send('haha')
haha
Out[45]: 1
In [46]: next(f)
None
Out[46]: 2
In [47]: f.send('haha')
haha
Out[47]: 3
- 使用__next__方法(不常用)
闭包(Closure):
什么是闭包?
在一个函数内部定义一个函数(称为内函数),内函数引用外部函数的变量或参数,这个内函数及引用到的变量和参数,就称为一个闭包。
def test(number): # 外函数
def inner(number_in): # 在外函数中定义一个内函数
print ("%s from inner" % number_in)
return number + number_in # 内函数引用了外函数的参数
return inner # 将内函数返回
def line_conf(a, b): # 定义外函数
def line(x): # 定义内函数
return a*x + b # 引用外函数参数
line1 = line_conf(1, 1) # x+1
line2 = line_conf(4, 5) # 4x+5
print(line1(5))
print(line2(5))
闭包思考...
- 闭包优化了变量,原本需要类对象完成的工作,闭包也可以完成
- 闭包引用了外部的局部变量,所以外部的局部变量无法及时释放,消耗内存
在闭包中修改外部函数的变量
def counter(start=0):
count = [start]
def incr():
nonlocal start # Python3中使用,声明该变量为nonlocal,非本地变量
count[0] += 1 # Python2中使用,利用可变类型的引用,来修改外部变量
start += 1
return count[0] # Python2方法
return start # Python3方法
return incr
装饰器(decorator):
- 装饰器是基于闭包来实现的,它是 Python 的一个语法糖。
- 定义一个函数(外函数),在函数中定义一个函数(内函数),外函数接收一个参数(是函数),在内函数中实现要新增的功能,内函数中必须调用传来的函数(外函数参数),从而实现对原函数功能的扩展。
什么时候使用?
当你需要扩展有一个函数的功能,却又不影响原本功能的情况下,使用装饰器是一个不错的选择。
示例
def log(func): # 定义外函数,接收一个参数(函数)
def wrapper(*args, **kwargs): # 定义内函数
print 'call %s()' % func.__name__ # 拓展的功能
return func(*args, **kw) # 调用传来的函数(在外函数接收)
return wrapper # 返回内函数
@log # 执行流程>> 1.先调用log函数,将now作为参数2.定义并返回内函数3.赋值给now,下次调用时相当于调用返回的内函数
def now():
print '2017-10-14'
# 调用now()函数,不仅会运行now()函数本身,还会在运行now()函数前打印一行日志:
IN>> now() # 执行流程>> 1.相当于执行了wrapper2.在wrapper中执行扩展的功能3.调用原本的函数
OUT>> call now()
2017-10-14
如果装饰器需要参数
def log(text):
def decorator(func):
def wrapper(*args, **kw):
print '%s %s():' % (text, func.__name__)
return func(*args, **kw)
return wrapper
return decorator
@log('execute')
#执行流程
#1.调用函数log('execute')
#2.返回函数decorator,此处变成@decorator
#3.将now传给decorator函数并调用
#4.返回wrapper函数
#5.赋值给now
def now():
print '2017-10-14'
类装饰器
class MyDecorator(object):
def __init__(self, func):
print("初始化")
self.func = func # 初始化时将传进的函数保存
def __call__(self, *args, **kwargs): # 再次调用test时,相当于调用实例化后的MyDecorator的对象,调用对象时,就会调用这个方法,在这个方法实现装饰器的功能即可
print("拓展功能开始")
self.func()
print("拓展功能结束")
@MyDecorator # 调用类并将test函数传入,相当于实例化MyDecorator,实例化后赋值给test
def test():
print ("---test---")
消除装饰器对文档的副作用
使用装饰器,对文档说明会有一些副作用,旧函数的文档会被覆盖,变成内函数的文档,下面的方法可以解决这个问题
import functools
def note(func):
"外函数"
@functools.wraps(func) # 通过functools模块的wraps方法来消除
def inner():
"内函数"
print("内函数")
return func()
return inner
@note
def test():
"测试函数"
print("这是测试函数")
应用场景
- 引入日志
- 函数执行时间计算
- 函数执行前处理
- 函数执行后清理
- 权限校验场景
- 缓存
多层装饰器执行顺序: 先调用内层装饰器
细节(Details):
作用域
- locals()函数会返回局部的命名空间
- globals()函数会返回全局的命名空间
LEGB 规则(locals -> enclosing function -> globals -> builtins)
在 Python 中,变量的查找顺序遵循 LEGB 规则,首先从 locals 局部变量开始查找,再从外部嵌套函数中查找,再从全局变量中找,最后从Python 的内建变量中查找。
==和 is
- ==判断的是值
- is 判断的是地址(id)
可变类型和不可变类型
1. 值一旦创建就不能被改变,任何“修改”实际都是创建了新的对象。
2. 常见类型:int、float、bool、str、tuple、frozenset、bytes、NoneType
可变类型:
1. 值可以直接修改,而不是创建新对象。
2. 常见类型:list、dict、set、bytearray、collections.deque
深拷贝和浅拷贝
浅拷贝: 只拷贝一层,地址不同
对于[1,2,3],浅拷贝和深拷贝都能拷贝,且拷贝后地址都不同。
对于[1,2,3,[6,6,6]],浅拷贝拷贝了第一层,内部的[6,6,6]只拷贝了引用;深拷贝进行了完整拷贝,内部的[6,6,6]也被重新创建了一份。
对于不可变类型:
浅拷贝:只拷贝引用,地址相同
深拷贝:只拷贝引用,地址相同
特殊情况:(1,2,3,[6,6,6])
浅拷贝: 只拷贝引用,地址相同
深拷贝: 完整拷贝,地址不同
私有化
Python 中的变量
- xx: 普通变量
- _x: 一个前置下划线,私有属性或方法,在 from xx import * 的时候不会导入,类对象和子类可以访问
- __xx: 两个前置下划线,避免与子类中的属性命名冲突,无法在外部直接访问(因为 Python 的名字重整(name mangling),子类不会继承
- __xx__: 两个前后下划线,魔法对象或属性。如:__init__就是一个魔法方法,开发时不自定义这种方法
- xx__: 两个后置下划线,用于避免与 python 关键字冲突
细节:其实__xx只是修改了变量名,并不是真正的访问不到,通过_Class__attr就可以访问
property
示例
class Money(object):
def __init__(self):
self.__money = 0
def getMoney(self):
return self.__money
def setMoney(self, value):
if isinstance(value, int):
self.__money = value
else:
print("error:不是整形数字")
money = property(getMoney, setMoney)
# 定义一个属性,当对money进行设置时调用setMoney,取值时调用getMoney方法
装饰器版本
class Money(object):
def __init__(self):
self.__money = 0
@property
def money(self):
#使用装饰器对money进行装饰,会自动添加一个名为money的属性,当对money进行取值时,会调用这个方法
return self.__money
@money.setter
def money(self, value):
#使用装饰器对money进行装饰,当对money设置值时,会调用这个方法
if isinstance(value, int):
self.__money = value
else:
print("error:不是整形数字")
垃圾回收(gc)
小整数对象池
intern 机制
靠引用计数维护说占用内存空间
如“Hello World”,定义 1000 遍,都是引用同一个地址
如果引用计数为 0,则释放
其他
Python 的垃圾回收策略
引用计数为主,标记-清除,分代收集机制为辅的策略
- 引用计数
- 一旦对象的引用计数为0,Python垃圾回收器会立刻启动,将内存还给操作系统。
- 缺点:
- 1 ) 增加了对内存空间的占用
- 2 ) 速度相对较慢
- 3)无法处理环形数据结构,也就是含有循环引用的数据结构
- 标记-清除
- 标记阶段。将所有的对象看成图的节点,根据对象的引用关系构造图结构。从图的根节点遍历所有的对象,所有访问到的对象被打上标记,表明对象是“可达”的。
- 清除阶段。遍历所有对象,如果发现某个对象没有标记为“可达”,则就回收。
- 分代收集
- 对象刚创建时为G0。
- 如果在一轮GC扫描中存活下来,则移至G1,处于G1的对象被扫描次数会减少。
- 如果再次在扫描中活下来,则进入G2,处于G2的对象被扫描次数将会更少。
- 零代链表
- 一代链表
- 二代链表
当某世代中分配的对象数量与被释放的对象之差达到某个阈值的时,将触发对该代的扫描。当某世代触发扫描时,比该世代年轻的世代也会触发扫描。
多进程
程序
编写完毕的代码,编译后的代码,在没有运行的时候,就称为程序。
进程
1 ) 正在运行的程序,就称为进程,进程是操作系统分配资源的基本单位。
2 ) 进程除了包含代码以外,还需要有运行的环境。
fork()
1 ) 只在Unix/Linux操作系统中可以使用
2 ) 创建一个子进程,复制父进程中的所有信息
3 ) 子进程永远返回0, 父进程返回子进程的id
4 ) 子进程可以通过getppid()获取父进程的id
multiprocessing()
进程间通信需要from multiprocessing import Queue
进程池的Queue在multiprocessing.Manager当中
pool()
apply_async 非阻塞式
apply 阻塞式
同步异步
同步就是在发出一个调用时,在没有得到结果之前,该调用就不返回
异步就是在调用发出之后,这个调用就直接返回了,不管有没有结果
阻塞非阻塞
与同步异步的区别: 同步异步关注的是消息通信的机制,阻塞非阻塞关注的是程序在等待调用结果时的状态
阻塞:调用结果返回之前,当前线程会被挂起
非阻塞:就是调用未得到结果之前,该调用不会阻塞当前线程
区分两个维度
分类维度 | 解释 |
|---|---|
| 同步 / 异步 | 是谁来“继续后续操作”? 同步:你自己继续执行(像调用函数) 异步:操作系统/框架帮你回调 |
| 阻塞 / 非阻塞 | 这个操作会不会“让你卡住”? 阻塞:会停下来等 非阻塞:不会停,先做别的去 |
多线程
一个程序至少有一个进程,一个进程至少有一个线程
对比
进程
1 ) 拥有独立的内存单元
2 ) 操作系统进行资源分配和调度的独立单位
3 ) 切换时耗费资源大
4 ) 需要的资源相对线程较多
5 ) 开销大,但利于资源管理和保护
线程
1 ) 线程必须依赖于进程运行,无法独立运行
2 ) CPU调度和分派的基本单位
3 ) 只拥有一点在运行中必不可少的资源(程序计数器,一组寄存器,栈)
4 ) 与同属一个进程的其他线程共享进程资源
5 ) 开销小,但不利于资源管理和保护
主线程结束不会造成子线程结束(因为进程还未结束)
线程共享全局变量,但会导致全局变量数据的混乱(线程非安全)
互斥锁
使用threading中的Lock类
好处:确保了某段代码只能由一个线程从头到尾完整地执行
坏处:阻止了多线程并发执行, 包含锁的某段代码实际上只能以单线程模式执行
多个锁的情况可能造成死锁
栈:先进后出
队列:先进先出
传递变量
使用全局字典
- 使用当前线程作为键(current_thread())
ThreadLocal
- 通过threading.local()创建ThreadLocal对象
import threading
local_variable = threading.local()
def process_student():
std = local_variable.student
print("%s, in %s" % (std, threading.current_thread().name))
def process_thread(name):
local_variable.student = name
process_student()
t1 = threading.Thread(target=process_thread, args=("小明"), name="A")
t2 = threading.Thread(target=process_thread, args=("小蓝"), name="B")
t1.start()
t2.start()
t1.join()
t2.join()
应用场景
为每一个线程绑定一个数据库连接,HTTP请求,用户身份信息等
ThreadLocal虽然是全局变量,但每一个线程都只能读写自己线程的独立副本,互不干扰。生产者消费者模式
- 生产者生产产品,并向仓库(queue)添加产品(消息)
- 消费者消费产品,并从仓库(queue)取出产品(消息)
- 只要仓库没满,生产者就可以继续生产,如果满了,生产者等待
- 只要仓库没空,消费者就可以取出产品消费,如果空了,消费者等待
为什么要使用?
当生产者和消费者的处理速度差距较大,就会有一方需要等待,为了解决这个问题,引入了生产者和消费者模式。
什么是生产者消费者模式?
通过一个容器来解决生产者和消费者的强耦合问题,生产者和消费者之间不直接通讯,通过阻塞队列来进行通讯,所有生产者生产完数据后不用等待消费者处理,直接放进队列,消费者也不需要找生产者要数据,而是直接从阻塞队列里取。阻塞队列就相当于一个缓存区,平衡了生产者和消费者的处理能力。
这个阻塞队列就是用来给消费者和生产者解耦的
全局解释器锁(Global Interpreter Lock)
GIL是Cpython解释器设计遗留下的历史问题。
任何线程在运行之前必须获取GIL,每当执行完100条字节码,或者遇上IO操作,GIL就会释放,切换到其他线程执行。
这样虽然保证了多线程访问公共资源的安全性,但是GIL使得Python中的多线程不能充分利用多核计算机的优势,无论有多少个核,只有一个GIL,同一时间只有一个线程获得GIL,也就是只有一个线程能够运行。
解决方式:
- 使用多进程,每个进程有一个GIL,互不影响。
- 通过C扩展实现。(C 扩展中释放 GIL 的操作(如 numpy))
- 其他解释器
Python 官方接受 PEP 703:计划在 3.13 支持 “可选禁用 GIL”
网络(NetWork)
网络协议
- OSI参考模型 七层
- TCP/IP协议 四层
- 示意
层级 名称 主要功能 举例 7 应用层 (Application) 提供用户服务接口 HTTP、FTP、SMTP、DNS 6 表示层 (Presentation) 数据格式转换、加解密、压缩等 SSL/TLS、JPEG、MP3 5 会话层 (Session) 建立、管理、终止会话 RPC、NetBIOS、Socket 会话控制 4 传输层 (Transport) 可靠传输、流量控制、差错恢复 TCP、UDP 3 网络层 (Network) 路由选择、逻辑寻址(IP 地址) IP、ICMP、IGMP 2 数据链路层 (Data Link) 物理寻址(MAC 地址)、帧同步、差错检测 Ethernet、PPP、交换机 1 物理层 (Physical) 比特流传输、电压信号、接口规范 网线、电缆、光纤、网卡、集线器 OSI层级 对应内容 应用层 你写好一封邮件 表示层 邮件内容编码成字节 会话层 建立你和收件人之间的通信会话 传输层 把信送上高速公路(TCP 拆包) 网络层 决定用哪条路去(IP 路由) 数据链路层 查收件人的门牌号(MAC) 物理层 实际快递传输过程(电信号)
- 示意
端口
标识一台电脑上不同的服务
端口有65535个,两个字节
- 知名端口
- HTTP:80
- FTP:21
- SSH:22
- 注册端口
- 1024~49151
- 分配给用户进程或应用进程
- 动态端口
- 49152~65535
使用netstat -an命令可以查看端口
ip地址
标识网络中不同的主机
ip地址的分类
- A类IP地址
- 1字节网络地址,3字节主机地址,网络地址以0开始
- B类IP地址
- 2字节网络地址,2字节主机地址,网络地址以10开始
- C类IP地址
- 3字节网络地址,1字节主机地址,网络地址以110开始
- D类IP地址
- 网络地址以1110开始
- E类IP地址
- 网络地址以1111开始
- 私有IP地址
- 只供局域网使用,不在公网中使用
- 10.0.0.0 ~ 10.255.255.255
- 172.16.0.0 ~ 172.31.255.255
- 192.168.0.0 ~ 192.168.255.255
127.0.0.1是本机地址
子网掩码:常用255.255.255.0作为子网掩码
组网设备
集线器:每个数据包都是以广播的方式发送的,容易造成网络堵塞
交换机:连接内网主机
- 转发过滤:发送到目标节点连接的端口
- 学习功能:将地址与相应的端口映射起来存放在交换机缓存中的MAC表中
ARP协议(地址解析协议):通过发送arp广播,得到IP地址对应的MAC地址
路由器:连接不同的网络
套接字(Socket)
UDP 用户数据报协议,是一个无连接的简单的面向数据报的传输层协议。UDP不保证可靠性,它只是把应用程序传给IP层的数据报发出去,但不保证他们能够到达目的地。由于无连接的特点,传输速度较快。
适用场景(注重速度):
1 ) 语音广播
2 ) 视频
3 ) QQ
4 ) TFTP
5 ) SNMP
6 ) RIP
7 ) DNS
创建UDP客户端程序的流程
- 创建套接字
- 传输数据
- 关闭套接字
#UDP发送数据示例
from socket import *
udp_socket = socket(AF_INET, SOCK_DGRAM) # AF_INET表示在Internet进程间通信, SOCK_DGRAM表示使用UDP协议
send_addr = ('192.168.64.56', 8888) # 端口号要使用数字
send_data = input("请输入要发送的数据")
udp_socket.sendto(send_data, send_addr)
udp_socket.close()
#UDP接收数据示例
from socket import *
udp_socket = socket(AF_INET, SOCK_DGRAM)
recv_data = udp_socket.recvfrom(1024) # 1024表示本次接收的最大字节数
print(recv_data)
udp_socket.close()
如果没有绑定端口号,每一次运行都会随机分配一个端口号,如果要使用固定的端口号,可以使用bind来进行绑定。
#绑定端口示例
from socket import *
udp_socket = socket(AF_INET, SOCK_DGRAM)
bind_addr = ('', 6666) # 要绑定的地址+端口号,ip不写,表示绑定本机的任何一个ip
udp_socket.bind(bind_addr) # 将元组作为参数传入
recv_data = udp_socker.recvfrom(1024)
print(recv_data)
udp_socket.close()
服务器与客户端
服务器:提供服务的一方,需要绑定端口
客户端:请求服务的一方,不需要绑定端口
UDP广播
from socket import *
dest = ('<broadcast>', 7788)
s = socket(AF_INET, SOCK_DGRAM)
s.setsockopt(SOL_SOCKET, SO_BROADCAST, 1)
s.sendto('Hi', dest)
TCP 传输控制协议,是一种面向连接,可靠的,基于字节流的通信协议。
TCP服务端的通信流程类似于生活中的手机
- 创建socket套接字(购买手机)
- 绑定ip和端口号(购买手机卡,确定了手机号)
- 设置为监听模式(将手机开机,设置为正常接听模式)
- 等待用户连接请求(等待电话拨入)
- 互相传输数据(通过手机对讲)
# TCP服务器示例
from socket import *
tcp_socket = socket(AF_INET, SOCK_STREAM) # 创建套接字
tcp_socket.bind(('', 8888)) # 绑定ip和端口号
tcp_socket.listen(5) # 设置为监听模式,参数5表示最多可以同时接收5个客户端的连接申请
new_socket, addr = tcp_socket.accept() # 通过accept取出对应的连接,取出对应的地址并创建相应的套接字
recv_data = new_socket.recv(1024) # 接收数据
print(recv_data) # 打印数据
new_socket.send("Thank you!".encode("gbk")) # 向客户端发送数据
tcp_socket.close() # 关闭套接字
TCP客户端的通信流程比较简单
from socket import *
tcp_client = socket(AF_INET, SOCK_STREAM) # 创建套接字
server_addr = ('192.168.64.56', 8888) # 服务器地址
tcp_client.connect(server_addr) # 向服务器请求连接
tcp_client.send("你好!".encode("gbk")) # 向服务器发送数据
recv_data = tcp_client.recv(1024) # 接收服务器发送过来的数据
print(recv_data) # 打印数据
tcp_client.close() # 关闭套接字
如果接收的数据长度为0,则意味着客户端关闭了连接。
三次握手
- 客户端向服务器发起连接请求
- 服务器对请求进行响应并确认(客户端--->>服务器的连接建立)
- 客户端接收到服务器发来的确认,并对服务器的连接请求进行确认(服务器--->>客户端的连接建立)
四次挥手
(这里的客户端和服务器不是绝对的,任何一方都可以发起断开连接的请求)
- 客户端发起断开连接的请求
- 服务器收到请求,断开连接并发回确认 (客户端--->>服务器的连接断开)
- 服务器将剩下的数据发送完毕,向客户端发起断开连接的请求
- 客户端断开连接并发回确认,进入TIME_WAIT等待状态,在2MSL之后,连接结束 (服务器--->>客户端的连接断开)
MSL:报文最大生存时间
为什么要等待2MSL?
因为有可能因为网络波动,导致对方没有收到最后一个包。对方将会在超时后重发第三次挥手的FIN包,主动关闭的一端在收到重发的FIN包后可以再发一个ACK应答包。在TIME_WAIT状态时,两端的端口不能使用,当连接处于2MSL等待阶段时,任何迟到的报文段都将丢弃。
短连接与长连接
短连接:一次连接一般只传递一次读写操作
- 建立连接-传输数据-关闭连接...建立连接-传输数据-关闭连接
- 优点:管理简单
- 缺点:如果客户请求频繁,将在TCP连接的建立和释放上占用大量时间和带宽
长连接:一次连接可以传递多次读写操作
- 建立连接-传输数据...(保持连接)...传输数据-关闭连接
- 优点:适合频繁请求的客户,节约时间和带宽,不需要频繁建立和释放连接
- 缺点:不容易管理,客户端的连接越来越多,服务器的压力也会越来越大
- 解决方法:为客户端机器设置最大连接数,释放一些长时间没有操作的连接
HTTP是无状态的协议
HTTP的长连接和短连接
在HTTP/1.0当中,默认使用短连接
从HTTP/1.1起,默认使用长连接
服务器(Server)
单进程服务器
# 单线程服务器示例
1 from socket import *
2
3 tcp_socket = socket(AF_INET, SOCK_STREAM)
4 local_addr = ('', 8888)
5 tcp_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
6 tcp_socket.bind(local_addr)
7 tcp_socket.listen(5)
8
9 while True:
10 toclient_socket, client_addr = tcp_socket.accept()
11 try:
12 while True:
13 recv_data = toclient_socket.recv(1024)
14 if len(recv_data) > 0:
15 print("收到数据%s" % recv_data.decode("gbk"))
16 else:
17 print("对方已关闭连接")
18 break
19 finally:
20 toclient_socket.close()
21 tcp_socket.close()
多进程服务器
# 多进程服务器示例
1 from socket import *
2 from multiprocessing import Process
3
4 def deal_with_client(new_socket):
5 while True:
6 recv_data = new_socket.recv(1024)
7 if len(recv_data) > 0:
8 print("收到数据:%s" % recv_data)
9 else:
10 print("对方已关闭连接!")
11 new_socket.close() # 对方退出后,关闭套接字
12 break
13
14 tcp_socket = socket(AF_INET, SOCK_STREAM)
15 tcp_socket.bind(('', 8888))
16 tcp_socket.listen(5)
17
18 while True:
19 new_socket, addr = tcp_socket.accept()
20 deal_process = Process(target=deal_with_client, args=(new_socket,))
21 deal_process.start()
22 new_socket.close() # 在新生成的套接字传到进程中之后,关闭套接字。因为创建新的进程会复制一份新的变量,所以需要关闭两次
23 tcp_socket.close()
多线程服务器
from socket import *
from threading import Thread
def dealWithClient(newSocket, destAddr):
while True:
recvData = newSocket.recv(1024)
if len(recvData) > 0:
print('recv[%s]:%s' % (str(destAddr), recvData))
else:
print('[%s]客户端已经关闭' % str(destAddr))
break
newSocket.close()
def main():
serSocket = socket(AF_INET, SOCK_STREAM)
serSocket.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
localAddr = ('', 7788)
serSocket.bind(localAddr)
serSocket.listen(5)
try:
while True:
print('-----主进程,等待新客户端的到来------')
newSocket, destAddr = serSocket.accept()
print('-----主进程,接下来创建一个新的进程负责数据处理[%s]-----' % str(destAddr))
client = Thread(target=dealWithClient, args=(newSocket, destAddr))
client.start()
# 因为线程中共享这个套接字,如果关闭了会导致这个套接字不可用
# 但是此时在线程中这个套接字可能还在收数据,因此不能关闭
# newSocket.close()
finally:
serSocket.close()
if __name__ == '__main__':
main()
单进程服务器-非阻塞
# 单进程非阻塞服务器示例
from socket import *
new_socket_list = [] # 创建一个列表,用来存放新连接的socket
tcp_socket = socket(AF_INET, SOCK_STREAM) # 创建服务器套接字
tcp_socket.bind(('', 9888)) # 绑定端口
tcp_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1) # 修改设置,允许端口重用
tcp_socket.listen(5) # 开启监听
tcp_socket.setblocking(False) # 设置tcp_socket套接字为非阻塞模式
while True: # 无限循环,轮询
try: # 捕获异常
new_socket_addr = tcp_socket.accept() # 使用accept获取新连接,因为是非阻塞,所以需要写在try里面
except:
pass # 报错直接忽略
else:
new_socket_addr[0].setblocking(False) # 如果没有报错,将新的连接套接字设置为非阻塞模式
new_socket_list.append(new_socket_addr) # 将新的套接字放到列表当中
need_delete_list = [] # 创建一个待删除列表,用来存放已经关闭的套接字
for new_socket, addr in new_socket_list: # 遍历新套接字列表
try:
recv_data = new_socket.recv(1024) # 获取数据
except:
pass
else:
if len(recv_data) > 0: # 如果有数据
print(recv_data)
else: # 如果对方关闭
print("对方已关闭连接!")
new_socket.close() # 关闭套接字
need_delete_list.append((new_socket, addr)) # 将该套接字放到待删除列表当中
for need_delete in need_delete_list: # 遍历待删除列表
new_socket_list.remove(need_delete) # 在新套接字列表当中删除所有已关闭的套接字,不在轮询
tcp_socket.close() # 关闭套接字
epoll服务器
- 优点
- 没有最大并发连接限制,能打开的FD(文件描述符,通俗的理解就是套接字对应的数字编号)远大于1024
- 效率较高,不是轮询的方式,不会因为连接的增加而降低效率。只有活跃的连接会调用callback,因此epoll只管理活跃的连接,效率远高于select和poll
#epoll服务器示例
import socket
import selecttcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 创建套接字
tcp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) # 设置端口重用
tcp_socket.bind(('', 8888)) # 绑定端口号
tcp_socket.listen(5) # 开启监听模式
epoll = select.epoll() # 创建epoll对象
epoll.register(tcp_socket.fileno(), select.EPOLLIN|select.EPOLLET) # 获取主套接字的文件描述符并注册,事件:可读 模式:ET
connections = {} # 创建一个连接字典,用来存放新连接的套接字
address = {} # 创建一个地址字典,用来存放新连接的套接字对应的地址
while True: # 循环等待客户端连接
epoll_list = epoll.poll() # 进行fd扫描,默认是阻塞等待,如果触发了已注册的事件,会返回一个元组(fd, event)
for fd, event in epoll_list: # 从元组中获取fd(文件描述符), event(事件)
if fd == tcp_socket.fileno(): # 如果是主套接字被触发,意味着有新的客户端请求连接
toclient_socket, addr = tcp_socket.accept() # 使用accept,获取新连接的套接字和地址
connections[toclient_socket.fileno()] = toclient_socket # 将套接字存进connections字典,以新套接字的文件描述符为键
address[toclient_socket.fileno()] = addr # 将地址存进address字典,以新套接字的文件描述符为键
epoll.register(toclient_socket.fileno(), select.EPOLLIN|select.EPOLLET) # 将新的套接字进行注册,事件:可读 模式:ET
elif event == select.EPOLLIN:
recv_data = connections[fd].recv(1024) # 如果第一个if不成立,意味着不是主套接字。如果是可读事件,就代表着客户端连接的套接字被触发,就可以用recv接收到数据
if len(recv_data) > 0: # 如果数据长度大于0,意味着有数据
print("收到数据:%s, 来自 %s, 地址 %s" % (recv_data, fd, address[fd])) # 打印数据
else: # 如果小于等于0,意味着对方关闭了连接
print("对方已关闭连接!") # 打印连接关闭提示
connections[fd].close() # 将对应的套接字关闭
del connections[fd] # 删除字典中的套接字
del address[fd] # 删除字典中的地址
EPOLLIN/EPOLLOUT/EPOLLET/EPOLLLT
EPOLLIN 是可读事件,从不可读转换到可读时,会触发。
EPOLLOUT 是可写事件,从不可写转换到可写时,会触发。
EPOLLET:当epoll检测到描述符事件发生并将此事件通知应用程序,应用程序必须立即处理该事件。如果不处理,下次调用epoll时,不会再次响应应用程序并通知此事件。
EPOLLLT:当epoll检测到描述符事件发生并将此事件通知应用程序,应用程序可以不立即处理该事件。下次调用epoll时,会再次响应应用程序并通知此事件。
协程(Coroutine)
什么是协程?
协程是比线程更小的执行单元,是轻量级的线程。协程自带CPU上下文,只要在合适的时机,我们就可以把一个协程切换到另一个协程,只要保存或恢复CPU上下文,程序就还可以运行。
通俗地说
线程当中的某个函数,可以在任何地方保存函数中的变量等信息,切换到另一个函数继续执行。注意,不是以调用函数的方式进行切换,并且切换的时机有开发者自行决定。
协程和线程
线程的切换不仅仅是保存和恢复上下文那么简单,操作系统为了程序高效运行,每个线程都会有自己的缓存Cache等数据,在切换线程的时候,操作系统还会帮你做这些数据的恢复操作。而协程的切换仅仅是上下文的切换,所以协程的切换相对线程而言,非常非常快。
协程的问题
操作系统并不会感知协程,所以协程的切换是个问题。
问题的解决
目前的协程框架大多是采用1:N的模式。
所谓1:N的模式,就是一个线程作为容器放置多个协程。而协程的切换,是协程自身决定的。
每个协程里面都有一个调度器,当这个协程发现自己执行不下去了(比如异步等待网络的数据回来,但数据还没有到),协程就会通知调度器,切换另一个协程执行。
新的问题
假设一个线程当中有一个协程是CPU密集型(框架中的协程遇上IO会自动切换)的,没有IO操作,那么它就不会主动触发调度器,其他协程就无法得到CPU,这个问题需要开发者来处理避免。
优点
协程可以解决当IO操作密集时,CPU频繁切换线程的问题。
把IO操作封装成一个协程,在触发IO操作时,会自动让出CPU给其他协程,而且协程的切换时很轻的,所以协程既保证了性能,又保证了代码的可读性。不过在CPU密集型的代码中,协程并没有什么好处。
Python 中的协程
在 Python 中,协程通常是通过 async 和 await 关键字实现的。async 用于定义协程函数,await 用于暂停执行并等待另一个协程的结果。
加了 await,协程可以“挂起”当前执行,等待一个耗时操作完成后继续执行,从而实现真正的异步并发、非阻塞。
示例:
python
CopyEdit
import asyncio # 定义一个协程函数 async def say_hello(): print("Hello") await asyncio.sleep(1) # 模拟异步操作 print("World") # 创建一个事件循环并运行协程 async def main(): await say_hello() # 运行协程 asyncio.run(main())
不加 await(同步方式):
python
CopyEdit
import asyncio import time async def download(name): print(f"Start {name}") time.sleep(2) # 阻塞操作 print(f"End {name}") async def main(): await download("page1") await download("page2") asyncio.run(main())
- time.sleep(2) 是阻塞操作。
- 执行时间 ≈ 4 秒
- 不能并发,只能一个一个来。
加了 await + 异步操作(协程意义体现):
python
CopyEdit
import asyncio async def download(name): print(f"Start {name}") await asyncio.sleep(2) # ⬅️ 这里是关键 print(f"End {name}") async def main(): await asyncio.gather( download("page1"), download("page2") ) asyncio.run(main())
- await asyncio.sleep(2) 是非阻塞的协程等待。
- 执行时间 ≈ 2 秒
- 并发执行了两个协程。
本质说明
await 的作用:
- await 后面必须是一个协程对象(或支持 __await__ 的对象)
- await 表示:挂起当前协程,等后面的操作执行完再回来继续
- 挂起期间,事件循环可以调度其他协程,实现并发
HTTP服务器
什么是HTTP协议?
HTTP协议,就是在网络上传输超文本的协议,HTTP是无连接,无状态的应用层协议。浏览器与服务器之间的通信采用的就是HTTP协议。
HTML是一种用来定义网页的文本。
无连接是指每次请求用完连接就释放。
无状态是指每次请求不记得上次的内容(可以用 Cookie/Session 保持)
WSGI(web server gateway interface)
WSGI只要求开发者实现一个函数,就可以相应HTTP请求。
WSGI 就是连接 Web 服务器(如 Nginx+uWSGI) 和 Web 应用框架(如 Flask、Django)的桥梁。
关于 ASGI
- ASGI 是用于支持异步(async/await)、WebSocket 的 Python Web 服务器接口规范,是对 WSGI 的升级。
你写了一个 Python 网站(比如 Flask 应用),这个网站本身不能直接处理 HTTP 请求,它需要一个“服务员”(Web 服务器)来把请求交给它处理。
浏览器
↓
Nginx (或 Apache)
↓ [反向代理]
uWSGI / Gunicorn(WSGI服务器)
↓ [WSGI 协议]
Flask / Django(WSGI应用)
示例代码(最小 WSGI 应用):
def application(environ, start_response): start_response('200 OK', [('Content-Type', 'text/plain')]) return [b'Hello WSGI']
这个 application 就是 WSGI 规定的入口函数。
为什么 WSGI 很重要?
- 标准化接口:任何支持 WSGI 的服务器都能运行你的 Python Web 应用;
- 解耦:Web 应用(如 Django)不需要关心 TCP/HTTP 的细节,只处理业务逻辑;
- 兼容性好:Flask、Django、Bottle 等框架都遵循 WSGI 标准;
- 部署灵活:结合 uWSGI、Gunicorn、Nginx 使用,生产部署很方便。
WSGI 就是这两者之间的“约定”:
- Web服务器 把 HTTP 请求(翻译成标准格式)交给 Python 程序
- Python 程序 处理后再返回响应内容
#符合WSGI标准的HTTP处理函数示例
#application必须由WSGI服务器来调用
#environ: 一个包含所有HTTP请求信息的dict对象
#start_response: 一个发送HTTP响应的函数
def application(environ, start_response):
start_reponse('200 OK', [('Content-Type', 'text/html')])
return 'Hello World!'
#coding=utf-8
import socket
import sys
from multiprocessing import Process
import re
class WSGIServer(object):
addressFamily = socket.AF_INET
socketType = socket.SOCK_STREAM
requestQueueSize = 5
def __init__(self, serverAddress):
#创建一个tcp套接字
self.listenSocket = socket.socket(self.addressFamily,self.socketType)
#允许重复使用上次的套接字绑定的port
self.listenSocket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
#绑定
self.listenSocket.bind(serverAddress)
#变为被动,并制定队列的长度
self.listenSocket.listen(self.requestQueueSize)
self.servrName = "localhost"
self.serverPort = serverAddress[1]
def serveForever(self):
'循环运行web服务器,等待客户端的链接并为客户端服务'
while True:
#等待新客户端到来
self.clientSocket, client_address = self.listenSocket.accept()
#方法2,多进程服务器,并发服务器于多个客户端
newClientProcess = Process(target = self.handleRequest)
newClientProcess.start()
#因为创建的新进程中,会对这个套接字+1,所以需要在主进程中减去依次,即调用一次close
self.clientSocket.close()
def setApp(self, application):
'设置此WSGI服务器调用的应用程序入口函数'
self.application = application
def handleRequest(self):
'用一个新的进程,为一个客户端进行服务'
self.recvData = self.clientSocket.recv(2014)
requestHeaderLines = self.recvData.splitlines()
for line in requestHeaderLines:
print(line)
httpRequestMethodLine = requestHeaderLines[0]
getFileName = re.match("[^/]+(/[^ ]*)", httpRequestMethodLine).group(1) # 获取请求的文件名
print("file name is ===>%s"%getFileName) #for test
if getFileName[-3:] != ".py": # 如果不是以.py结尾,则是静态文件
if getFileName == '/': # /转向index
getFileName = documentRoot + "/index.html"
else: # 不是/,将文件名与documentroot路径拼接
getFileName = documentRoot + getFileName
print("file name is ===2>%s"%getFileName) #for test
try: # 捕获异常,因为文件可能不存在
f = open(getFileName) # 尝试打开文件
except IOError: # 打开失败,表示文件不存在,返回404
responseHeaderLines = "HTTP/1.1 404 not found\r\n"
responseHeaderLines += "\r\n"
responseBody = "====sorry ,file not found===="
else: # 打开成功,表示文件存在,返回200
responseHeaderLines = "HTTP/1.1 200 OK\r\n"
responseHeaderLines += "\r\n"
responseBody = f.read()
f.close()
finally: # 不管是否成功,都要向客户端发送数据,并关闭套接字
response = responseHeaderLines + responseBody
self.clientSocket.send(response)
self.clientSocket.close()
else:
#处理接收到的请求头
self.parseRequest()
#根据接收到的请求头构造环境变量字典
env = self.getEnviron()
#调用应用的相应方法,完成动态数据的获取
bodyContent = self.application(env, self.startResponse) # 获取到响应体
#组织数据发送给客户端
self.finishResponse(bodyContent) # 完成数据构造
def parseRequest(self):
'提取出客户端发送的request'
requestLine = self.recvData.splitlines()[0]
requestLine = requestLine.rstrip('\r\n')
self.requestMethod, self.path, self.requestVersion = requestLine.split(" ")
def getEnviron(self):
env = {}
env['wsgi.version'] = (1, 0)
env['wsgi.input'] = self.recvData
env['REQUEST_METHOD'] = self.requestMethod # GET
env['PATH_INFO'] = self.path # /index.html
return env
def startResponse(self, status, response_headers, exc_info=None): # 构造响应头
serverHeaders = [
('Date', 'Tue, 31 Mar 2016 10:11:12 GMT'),
('Server', 'WSGIServer 0.2'),
]
self.headers_set = [status, response_headers + serverHeaders]
def finishResponse(self, bodyContent):
try:
status, response_headers = self.headers_set
#response的第一行
response = 'HTTP/1.1 {status}\r\n'.format(status=status)
#response的其他头信息
for header in response_headers:
response += '{0}: {1}\r\n'.format(*header)
#添加一个换行,用来和body进行分开
response += '\r\n'
#添加发送的数据
for data in bodyContent:
response += data
self.clientSocket.send(response)
finally:
self.clientSocket.close()
#设定服务器的端口
serverAddr = (HOST, PORT) = '', 8888
#设置服务器静态资源的路径
documentRoot = './html'
#设置服务器动态资源的路径
pythonRoot = './wsgiPy'
def makeServer(serverAddr, application):
server = WSGIServer(serverAddr)
server.setApp(application)
return server
def main():
if len(sys.argv) < 2:
sys.exit('请按照要求,指定模块名称:应用名称,例如 module:callable')
#获取module:callable
appPath = sys.argv[1]
#根据冒号切割为module和callable
module, application = appPath.split(':')
#添加路径套sys.path
sys.path.insert(0, pythonRoot)
#动态导入module变量中指定的模块
module = __import__(module)
#获取module变量中制定的模块的application变量指定的属性
application = getattr(module, application)
httpd = makeServer(serverAddr, application)
print('WSGIServer: Serving HTTP on port {port} ...\n'.format(port=PORT))
httpd.serveForever()
if __name__ == '__main__':
main()
正则表达式(Regular Expression)
用来描述一组计算机能够识别的字符串规则。
查询方法
match从头开始匹配,如果开头不匹配就直接返回None
search从任意位置开始匹配一个,只要字符串中有匹配的字符,就能匹配成功
findall找出所有匹配的,返回列表
sub将匹配到的数据替换成指定的字符串,第二个参数可以是函数
#sub函数作参数示例
import re
def add(temp):
str_num = temp.group()
num = int(str_num) + 1
return str(num)
ret = re.sub(r'\d+', add, 'python = 997')
print(ret) # 998
ret = re.sub(r'\d+', add, 'python = 99')
print(ret) # 100
split根据指定的规则对字符串进行切割
原始字符串
python中的一个反斜杠需要用'\\'表示,如果正则要匹配到这个反斜杠,就要这样写re.match('\\\\', '\\')
这样写严重降低了代码的可读性,解决方法就是使用原始字符串,在字符串前加个r,re.match(r'\\','\\')
匹配分组
| 匹配左右任意一个表达式
(ab) 将括号中的字符作为一个分组
\num 引用分组num到字符串
(?P<name>) 分组起别名
(?P=name) 引用别名为name的分组
贪婪与非贪婪
贪婪:在符合规则的情况下尽可能多地匹配
非贪婪:在符合规则的情况下尽可能少地匹配
python中的数量词默认是贪婪的
如何把贪婪变成非贪婪?
在数量词后加上'?',就能使贪婪变成非贪婪
数据库(Database)
SQL结构化查询语言(不区分大小写)
- DQL数据查询语言,select
- DML数据操作语言,update,delete,insert
- TPL事物处理语言,begin,commit,rollback
- DCL数据控制语言,grant,revoke
- DDL数据定义语言,create,drop
- CCL指针控制语言,declare cursor
优点
- 可移植性强
- 为多种语言提供了API
- 支持多线程
- 优化的SQL查询算法,有效地提高查询速度
- 提供多语言支持
- 提供TCP/IP、ODBC、JDBC等多种数据库连接途径
- 支持多种存储引擎
- 开源
- 免费
数据类型
使用数据类型的原则:够用就行,尽量使用取值范围小的,节省存储空间
常用数据类型
- 整数:int, bit
- 小数:decimal
- 字符串:varchar, char
- 日期:date,time,datetime
- 枚举类型:enum
约束
- 主键primary key
- 非空not null
- 唯一unique
- 默认default
- 外键foreign key
- 说明:外键约束可以保证数据的有效性,但在进行crud时,都会降低数据库的性能,所以不推荐使用,数据的有效性可以在逻辑层控制。
字段的增删查改
增:alter table 表名 add 列名 类型;
改-重命名:alter table 表名 change 原名 新名 类型;
改-不重命名:alter table 表名 modify 列名 类型及约束;
删:alter table 表名 drop 列名;
查看表的创建语句
show create table 表名;
数据操作(Crud)
增insert
删delete
查select
改update
自动增长列需要一个占位符,通常使用0,default,null来占位。
备份
- mysqldump -uname -ppwd 数据库名 -> filename.sql
恢复
- mysql -uname -ppwd 数据库名 <- filename.sql
三范式
- 第一范式 (1NF):列不可分割(关系数据库的基本要求)
- 第二范式(2NF):表中每个实例或记录必须可以被唯一地区分
- 第三范式(3NF):任何非主属性不依赖其他非主属性,即引用主键
E-R模型
- E-entry:实体
- 设计实体就像定义一个类,一个实体可以转换成数据库中的一张表
- R-relationship:关系
- 描述两个实体之间的对应规则,关系类型包括,一对一,一对多,多对多
- 关系也是一种数据,需要通过一个字段存储在表中
- A对B一对一
- 在A或B中创建一个字段,存储另一个表的主键值
- A对B一对多
- 在B中创建一个字段,存储另一个表的主键值
- A对B为多对多
- 新建表C,拥有两个字段,一个存储表A的主键值,一个存储表B的主键值
逻辑删除
对于某些重要的数据,不希望物理删除,可以使用逻辑删除
实现方法:设置一个isDelete字段,类型为bit,表示逻辑删除,默认为0
MySQL
#使用distinct可以去除重复的行
select distinct gender from students;
#完整的查询语句
-- 完整的查询语句
/*完整的查询语句*/
SELECT select_expr [,select|_expr,...] [
FROM tb_name
[WHERE 条件判断]
[GROUP BY {col_name | postion} [ASC | DESC], ...]
[HAVING WHERE 条件判断]
[ORDER BY {col_name|expr|postion} [ASC | DESC], ...]
[ LIMIT {[offset,]rowcount | row_count OFFSET offset}]
]
模糊查询
# like
select * from students where name like '黄%'; # % 表示任意多个字符
select * from students where name like '黄_'; # _ 表示任意一个字符
范围查询
select * from students where id in(1,3,8); # in表示在一个非连续的范围内
select * from students where id between 3 and 8; # between ... and ... 表示在一个连续的范围内
空判断
select * from students where height is null; # null与''是不同的
select * from students where height is not null; # is not null 非空
优先级
- 由高到低:小括号、not、比较运算符、逻辑运算符
- and比or先运算,如果希望or先算,需要使用小括号
排序
select * from 表名 order by 列1 asc|desc, 列2 asc|desc,... # 语法 asc从小到大排列,desc从大到小排列
聚合函数
count(*) # 计算总行数
# 示例
select count(*) from students;
-- ------------------------------------
max(列) # 求此列的最大值
# 示例
select max(id) from students where gender=0;
-- ------------------------------------
min(列) # 求此列的最小值
# 示例
select min(id) from students where isdelete=0;
-- ------------------------------------
sum(列) # 求此列之和
# 示例
select sum(id) from studetns where gender=1;
-- ------------------------------------
avg(列) # 求此列平均值
select avg(id) from students where isdelete=0 and gender=0;
分组
# 语法
select 列1,列2,聚合... from 表名 group by 列1,列2...
# 示例
select gender as 性别,count(*) from students group by gender;
分组后数据筛选
select 列1,列2,聚合... from 表名 group by 列1,列2,列3... having 列1,...聚合...
# 示例
select gender as 性别, count(*) from students group by gender having gender=1;
#获取部分行
select * from 表名 limit start,count; # 从start开始,取count条数据
# 示例
select * from students where gender=1 limit 0,3;
# 分页
select * from students where isdelete=0 limit (n-1)*m, m
where和having
where是对from指定的表进行数据筛选,属于对原始数据进行筛选
having是对group by的结果进行筛选
连接查询
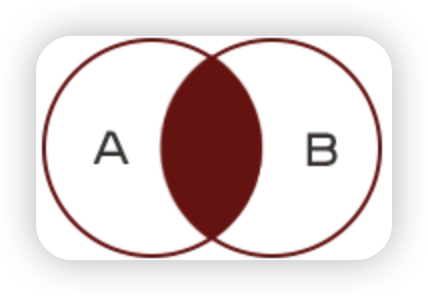
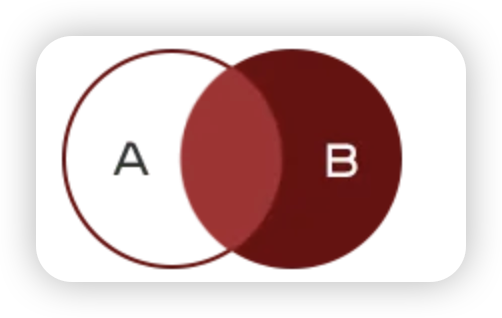
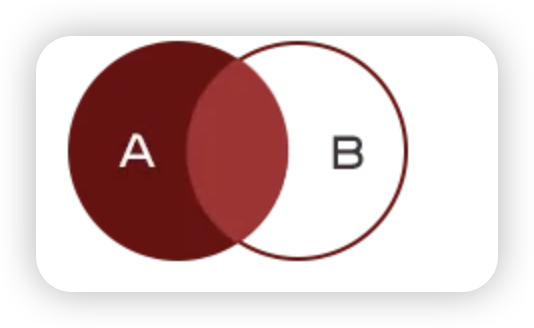
当查询结果来自于多张表时,需要将多张表连接起来
- 内连接查询:查询结果为两个表匹配到的数据
- 右连接查询:查询结果为两个表匹配到的数据,右表特有的数据,对于左表中不存在的数据使用null填充
- 左连接查询:查询结果为两个表匹配到的数据,左表特有的数据,对于右表中不存在的数据使用null填充
上代码吧
select * from 表1 inner或left或right join 表 on 表1.列=表2.列;
#内连接示例
select * from students inner join pythons on students.cls_id = pythons.id;
#上面的语句将学生表和班级表按照班级id进行内连接,两表id都能够对上才能匹配出来
-- -------------------------------------------------------------------
#左连接示例
select * from students left join pythons on students.cls_id = pythons.id;
#上面的语句将学生表和班级表按照id进行左连接,只要左表(students)中有的id,就能匹配出来,如果右表中没有,就填充null
-- -------------------------------------------------------------------
#右连接示例
select * from students right join pythons on students.cls_id = pythons.id;
#上面的语句将学生表和班级表按照id进行右连接,只要右表(classes)中存在的,就能匹配出来,如果左表中没有,就填充null
自关联
一张表将自身视为另一张表,自己与自己进行连接,就是自关联。
#表结构
create table areas(
aid int primary key,
atitle varchar(20),
pid int
);
#查询一共有多少个省
select count(*) from areas where pid is null;
#查询省名称为‘广东省’的所有城市
select city.atitle from areas as city inner join areas as province on city.pid=province.aid where province.atitle='广东省';
#查询市名称为'深圳市'的所有区县
select dis.atitle from areas as dis inner join areas as city on city.id=dis.pid where atitle='深圳市';
子查询
在一个select语句中,嵌入另外一个select语句,被嵌入的select就称为子查询语句。主要查询的对象则称为主查询。
- 标量子查询:子查询返回结果是一个数据(一行一列)
- 列级子查询:子查询返回结果是一列数据(一列多行)
- 行级子查询:子查询返回结果是一行数据(一行多列)
- 表级子查询:子查询返回结果是多行多列
- 很多表级子查询都能够用连接查询实现,这种时候推荐使用连接查询,更简洁清晰。
# 行级子查询
# 查询班级中年龄最大,身高最高的学生
select * from students where(age, height) = (select max(age), max(height) from student);
子查询中特定关键字使用
in 范围
主查询 where 条件 in (列子查询)
any | some 任意一个
主查询 where 列 = any (列子查询)
all
主查询 where 列 = all(列子查询) 等于里面所有
主查询 where 列 <> all(列子查询) 不等于其中所有
通过子查询插入数据
insert into goods_cate (cate_name) select cate from goods group by cate;
# 通过子查询插入数据,不需要values关键字。
# 通过create...select 来写入数据,一步到位
create table goods_brands (
brand_id int unsigned primary key auto_increment,
brand_name varchar(40) not null) selelct brand_name from goods group by brand_name;
# 更新已存在表的外键约束
alter table goods add foreign key(cate_id) references goods_cates(cate_id);
alter table goods add foreign key(brand_id) references goods_brands(brand_id);
# 删除已存在的外键
alter table goods drop foreign 外键名;
# show create table 表名; 可以查看外键名
使用外键可能会降低表更新的效率
Mysql语句的执行顺序
- from 表名
- where ...
- group by ...
- select distinct ...
- having ...
- order by ...
- limit ...
关于数据库常见的安全问题
- SQL注入:不合法输入,如单引号
- 撞库:利用从别处得到的账户密码,尝试在另一个网站上登录
- 攻击服务器的安全漏洞
安全建议
- 存储密码必须加密(针对数据库设计)
- 登录时添加验证码(针对Web开发者)
- 在多个站点间使用不同的密码(针对普通用户)
函数:
可以在crud语句中使用
存储过程:
需要使用call调用
delimiter $$ # 设置分割符,默认为分号
create function name(args_list) returns 返回类型
begin
sql语句
end
$$
delimiter ;
相同点:
- 两者都是为了可重复执行的操作数据库的sql语句的集合
- 编译一次后都会被缓存起来,不需要重复编译
- 减少网络交互,减少网络访问流量
不同点:
- 标识符不同,function和procedure
- 函数必须有返回值,存储过程没有返回值
- 函数需要使用select,存储过程要使用call来调用
- 存储过程中可以调用select,而函数中除了select...into之外的select语句都无法调用
- 存储过程可以通过设置in,out参数,使得更加灵活,可以返回多个结果
视图
本质就是对查询的封装
#创建视图
create view 视图名 as select语句;
#查看视图
show tables; # 查看表会将所有的视图也列出来
#删除视图
drop view 视图名;
#使用视图
select * from 视图名;
事物(Transaction)
为什么需要事物?
一个转账案例,A转500元给B:
- 首先,系统检查A的余额是否大于等于500
- 在A中扣除500
- 在B中增加500
- 转账完成
如果流程正常走完,那就皆大欢喜,但是如果系统故障了呢?
流程正常走完,有一个隐藏的前提条件,就是A扣钱,B加钱,要么同时完成,要么同时失败。这就是事物的需求。
事物的四大特性(ACID)
- 原子性(Atomicity)
- 事物的所有操作不可分割,要么全部完成,要么全部失败
- 一致性(Consistency)
- 事务在执行前后,数据库的状态应始终保持一致。如果事务执行前数据库处于一致性状态,那么事务执行完毕后也应该处于一致性状态
- 一致性就是指数据库在事务开始和结束时,始终满足所有的约束和业务规则,确保数据的有效性和合法性。
- 隔离性(Isolation)
- 事物的执行不受其他事物的干扰,事物执行的中间结果对其他事物必须是透明的
- 持久性(Durability)
- 对于任意已提交的事物,系统必须保证该事物对数据库的改动不丢失,即使数据库出现故障