爬虫
- 什么是爬虫
- 模拟浏览器,发送请求,抓取信息
- 作用
- 数据采集
- 自动化测试
- 抢票抢商品等
- 投票
- 网络安全
- 短信轰炸
- 漏洞扫描
- 分类
- 数量
- 通用爬虫
- 聚焦爬虫
- 目的
- 功能性爬虫,完成功能
- 数据增量爬虫,获取数据
- 基于url变化
- 不论url是否变化
- 参考资料
- 虫师——自动化测试
- 流程
- url → 发送请求 → 解析响应
- → 提取链接 → 继续爬取
- → 提取数据 → 保存数据
- 常见的请求头和响应头
- 请求头
- Host 域名
- Connection 链接
- Upgrade-Insecure-Requests 升级为HTTPS
- User-Agent 用户代理
- Referer 页面跳转处,可用于防盗链
- Cookie
- Content-Type
- 响应头
- Set-Cookie
- 状态码
- 状态码不可信,以抓包和浏览器结果为准
- 浏览器和爬虫
- 浏览器发送请求后会自动发送后续请求并自动渲染
- 爬虫只会根据代码发送
- 所以爬虫需要进行抓包分析
- 抓包
- 分析页面渲染流程和架构,从中找出对应的请求,再解析响应,提取数据
- request模块
- text和content
- text: str类型,自动推测的编码类型和解码
- content: bytes类型,可以进行decode操作
- response.encoding = 'utf8' 可以设置响应的编码
- 中文乱码应对

- 常用属性和方法

- 使用
- headers设置请求头
- params设置请求参数
- cookies
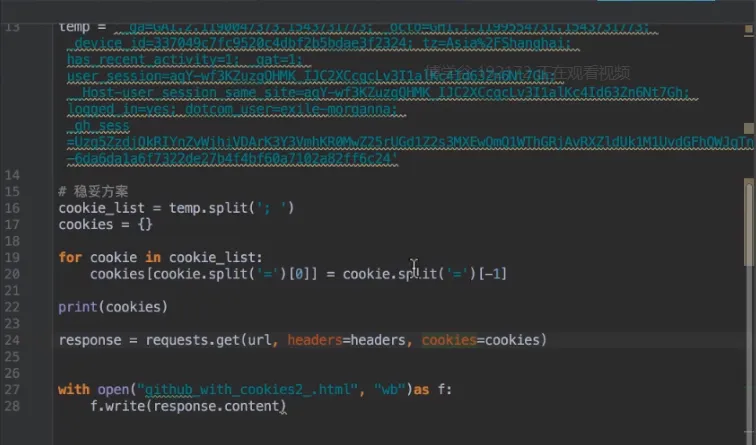

- 可以在请求头设置
- 在请求时设置cookies参数,值为字典对象(推荐)
- session
- 多次请求时进行状态保持
- request模块会在下次请求自动带上cookie
- timeout 超时时间,超时后请求失败
- proxies 接收字典
- verify 忽略证书认证
- cookieJar对象转换为字典

- 代理
- 正向代理
- 代理服务器帮助我们向目标服务器转发请求
- 反向代理
- 由代理服务器分配最终服务的处理服务器
- 透明代理: 目标服务器知道客户端和代理服务器
- 匿名代理: 目标服务器知道代理服务器
- 高匿代理: 目标服务器不知道代理服务器是代理
- post请求
- request(url, data)
- data是请求体
- 数据来源
- 固定值
- 输入值
- 预设值
静态文件
单独发请求获取
- 客户端生成
- 模拟登录
- 案例Github登录
- 获取登录token
- 发送请求
- 提取token
- 发送登录请求
- 存储cookie或session
- 数据提取
- 数据分类
- xml
- re
- lxml


- json
- json、re
- jsonpath
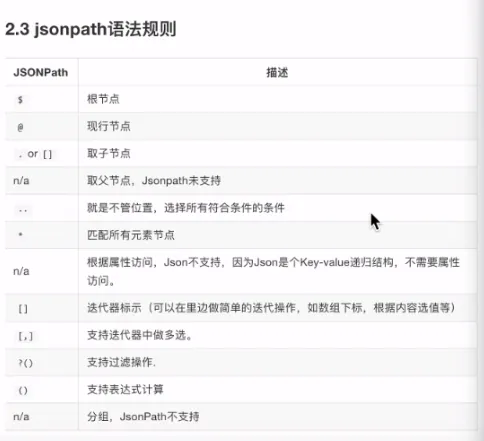
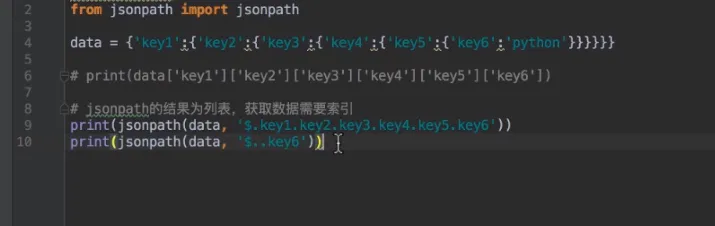
- 常用
$根节点
.子节点
..子孙节点
- 工具
- beautifulsoup 用于解析HTML和XML文档的Python库
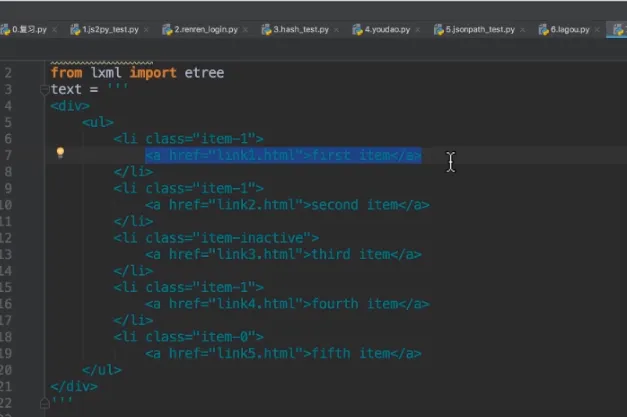
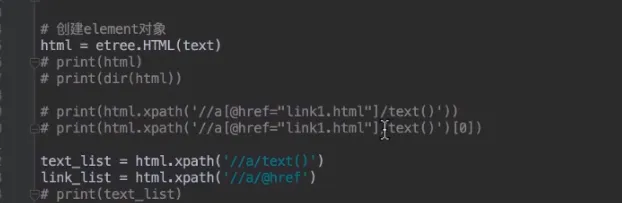
- xpath
- xpathhelper,第三方浏览器插件,测试xpath
- 语法

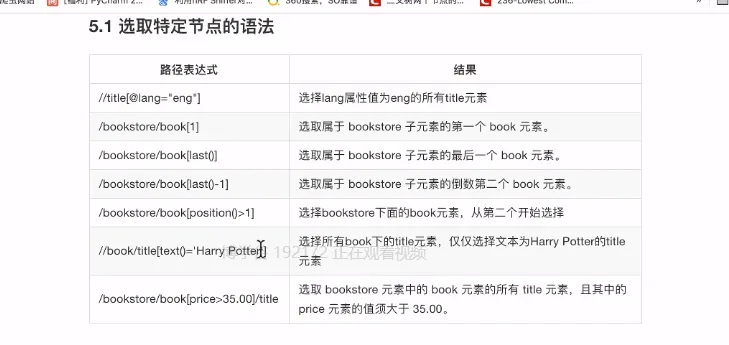
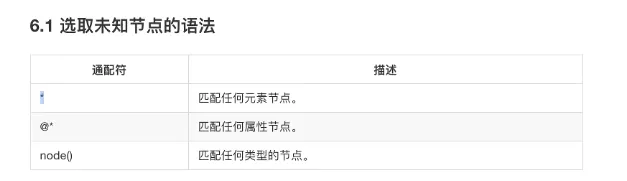
复合语法
//td/a|//h2/a

- 正则
- css选择器
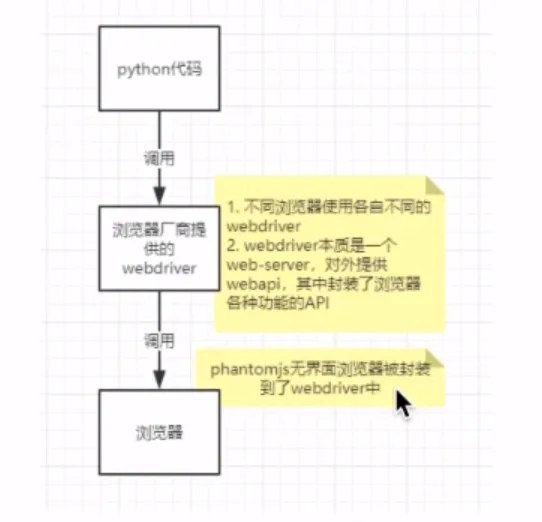
- Selenium
- selenium web自动化测试工具,可以直接调用浏览器
- phantomjs无界面浏览器,基于webkit
- 需要安装对应浏览器的webdriver
- 原理
- 安装
- 模块
- pip install selenium
- driver
- 确定浏览器版本
- 下载驱动
- 配置环境变量
- 常用属性和方法
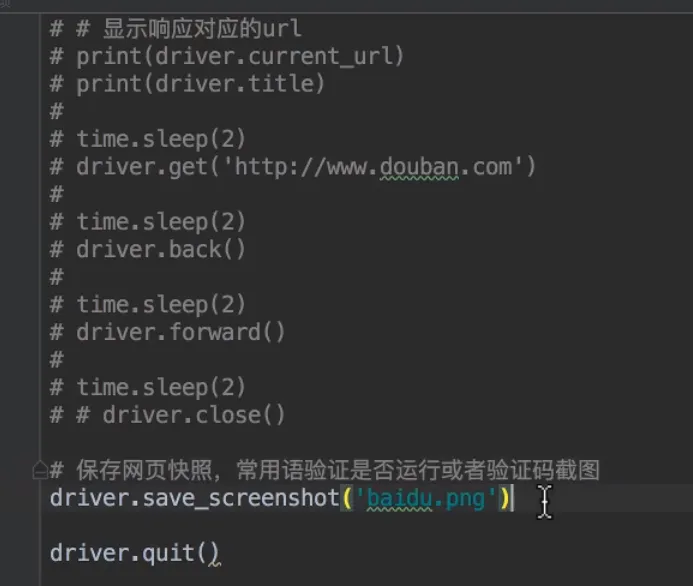
- 定位元素

- 提取内容和属性

- 窗口切换
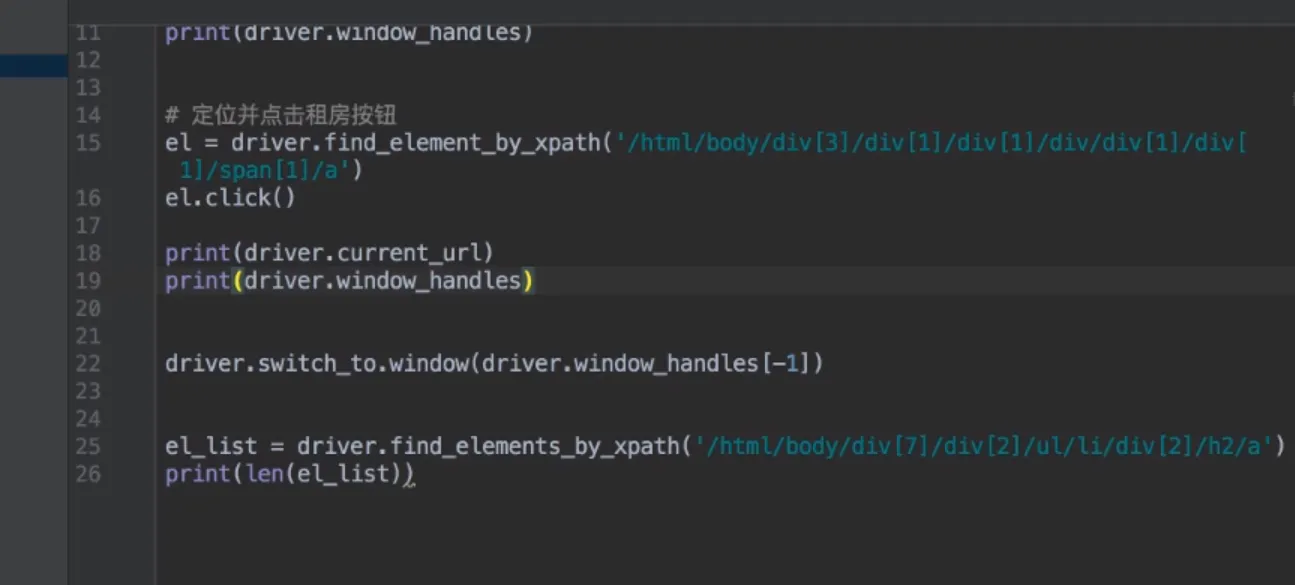
- 获取句柄
- 切换标签
- frame切换

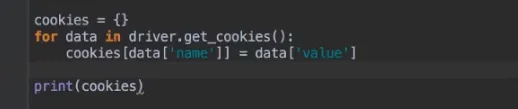
- cookie操作
- 执行JS
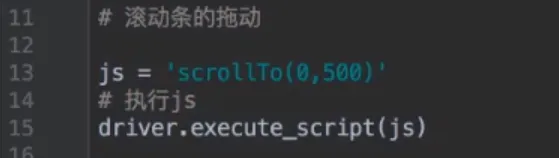
- 页面等待

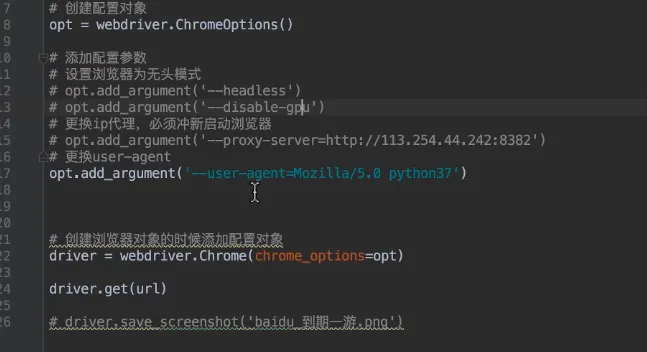
- 配置对象
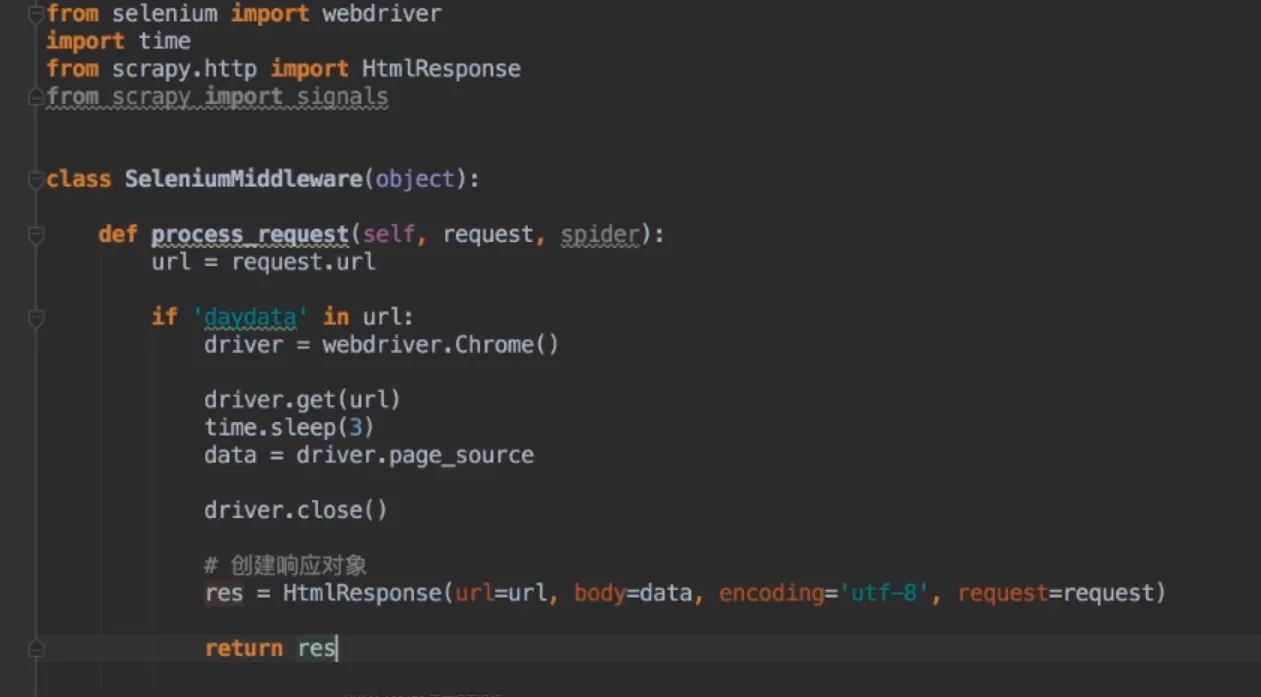
- 动态加载
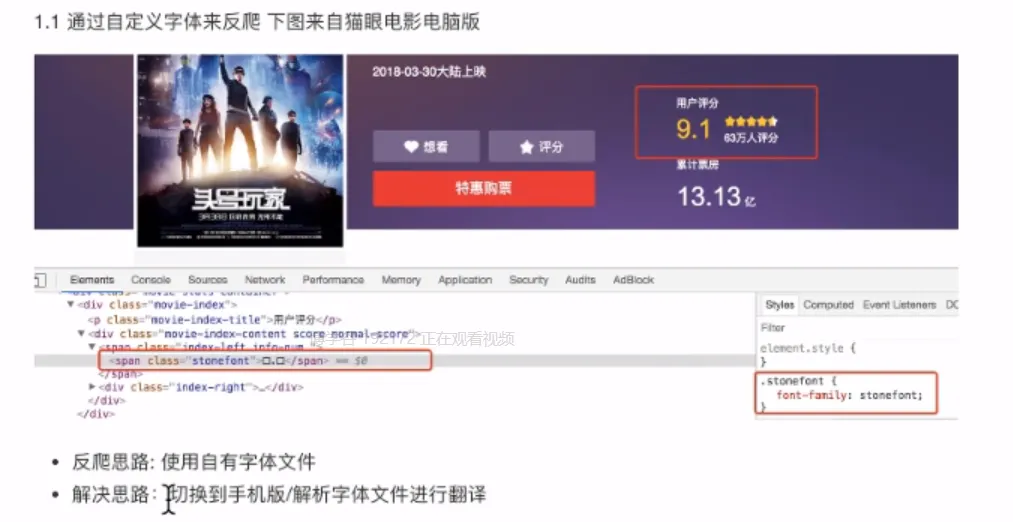
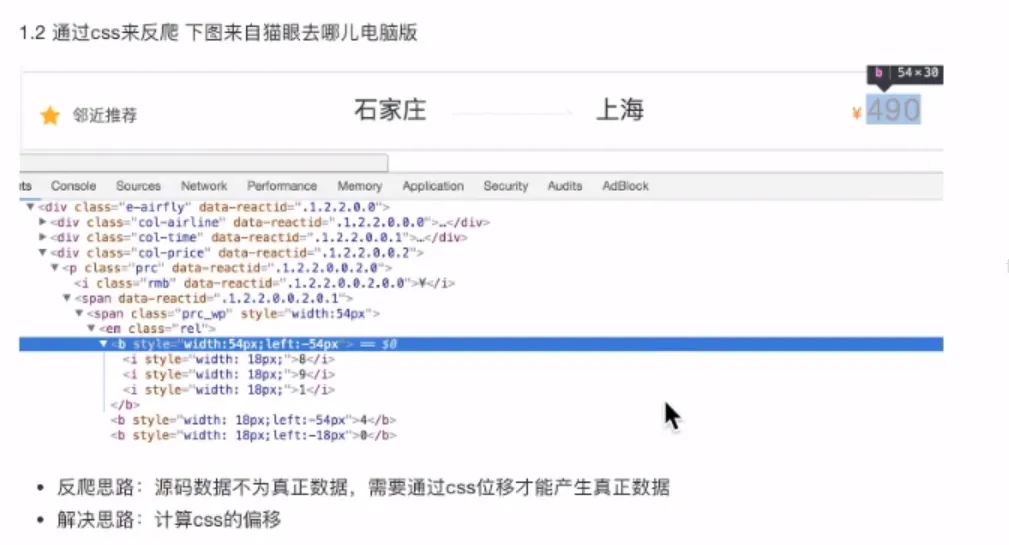
- 反爬及解决
- 原因
- 爬虫会浪费服务器资源,造成服务器负载
- 公司资源竞争力
- 概念

- 方向

- 方法
- 身份


- 行为



- 加密
- 图像识别引擎
- tesseract

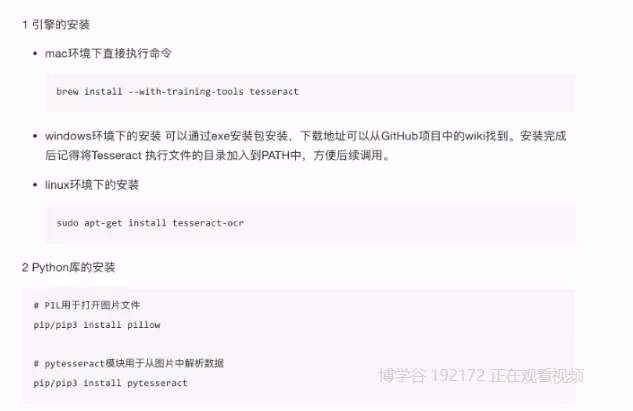
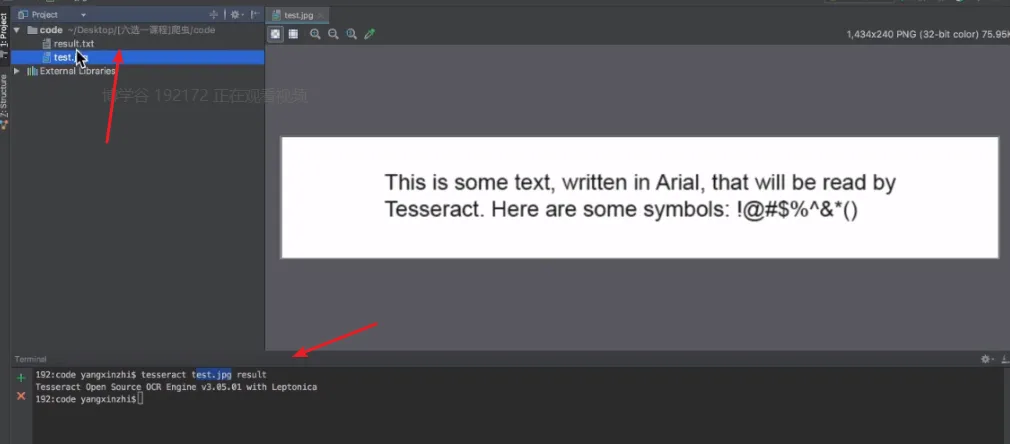
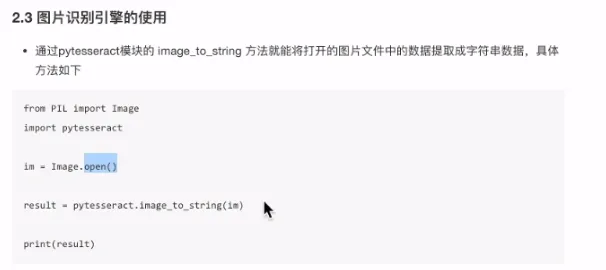
- 可以自行训练
- 打码平台
- 云打码
- 极验验证码
- 其他
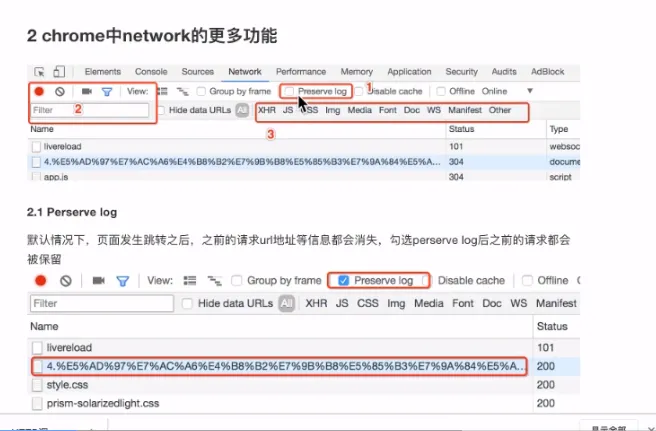
- 浏览器功能
- 隐身窗口
- 记录抓包记录
- 登录接口
- PC端
- 手机端(更容易找)
- 确定js位置
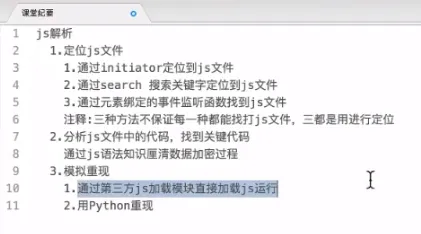
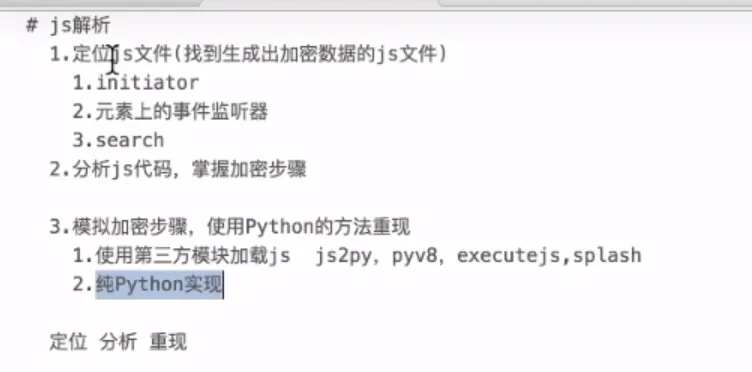
- js2py
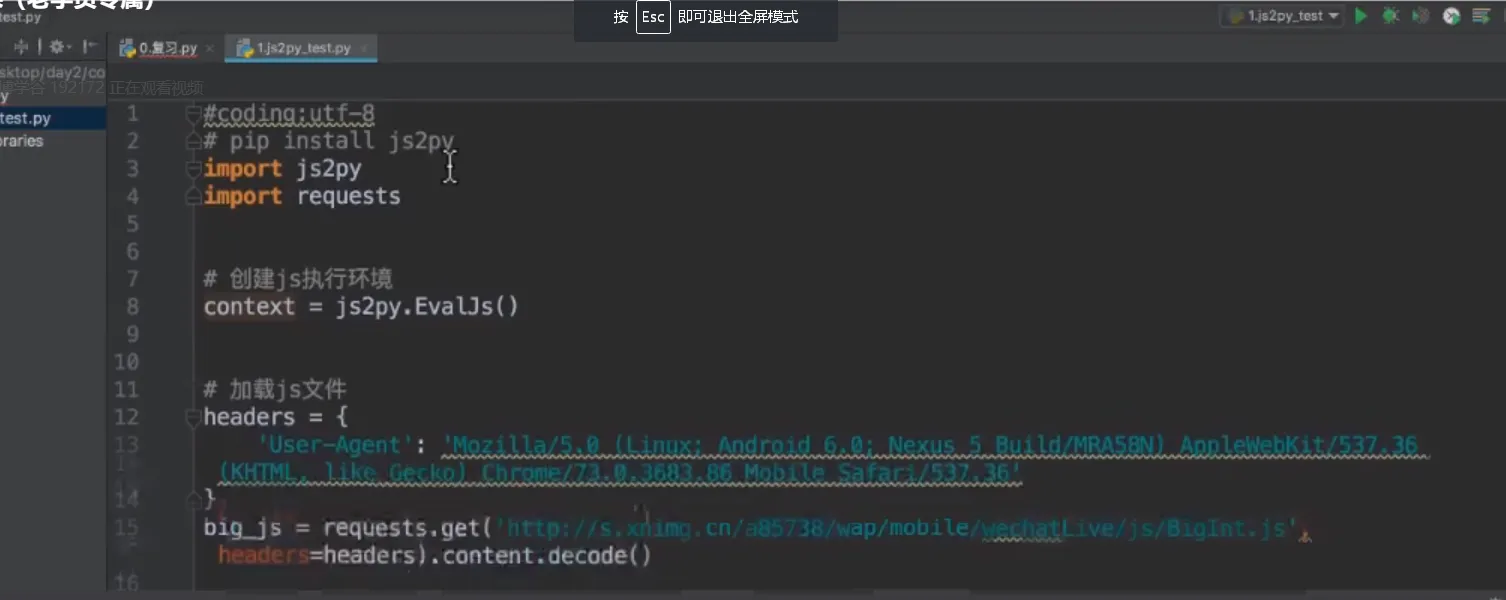

- hashlib可以用来去重
- 节省空间
- 布隆过滤器,基于hash,更节省空间
- 文本内容去重
- 编辑距离
- simhash
- Mongodb
- 适用海量存储
- sql和nosql的区别
- 表之间的关联关系
- 字段是否固定,提前定义
- 安装:apt-get install mongodb-org
- 端口:27017
- linux命令
- grep -v "#" /etc/mongod.conf 获取文件中非#号的行
- 启动

- 生产环境启动

- mongosh 交互
- 操作

- 基本操作
- db.createCollection(c_name)
- db.dropCollection(c_name)
- 插入
- db.c_name.save(document) 需要传带_id的文档,执行更新或插入(如果id不存在)
- db.c_name.insert(document) 插入
批量插入
db.c_name.insert(document_list)
document_list: [document, document, document...]
- 查询

- 运算符







- 更新
- db.c_name.update({})

- upsert 找到则更新,没有则插入
- db.c_name.update({})

- 删除

- 聚合
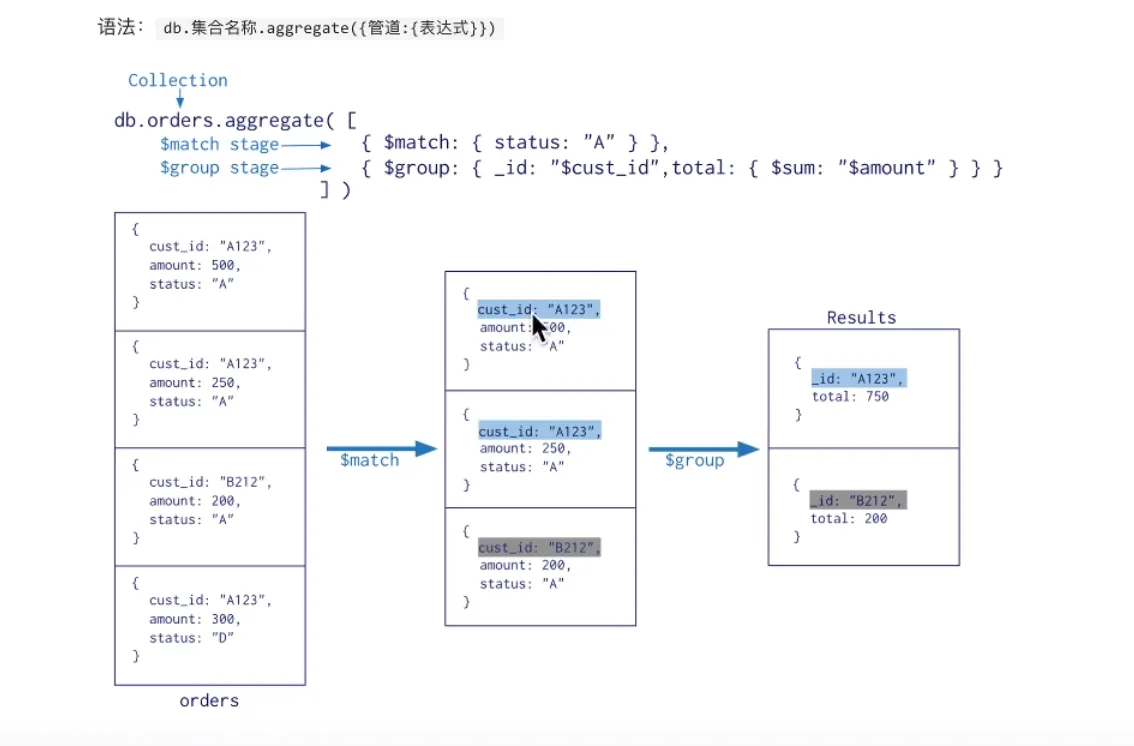
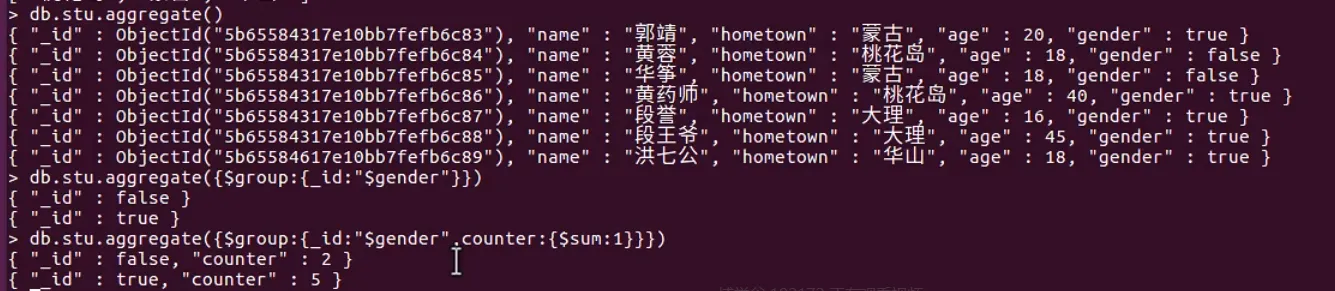
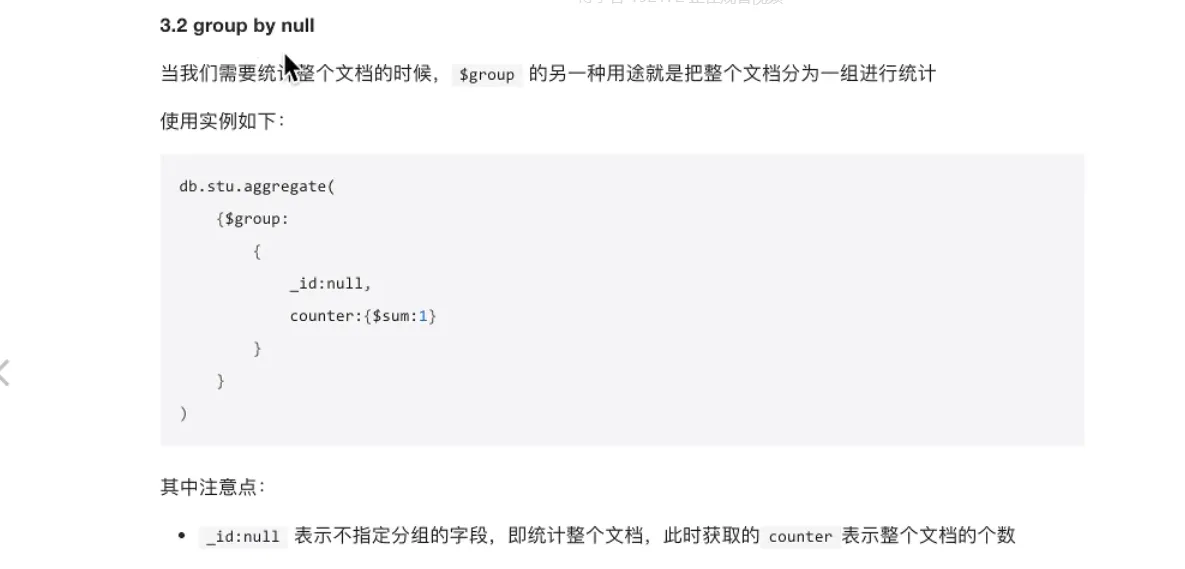

- 管道

- 表达式

- unwind拆分
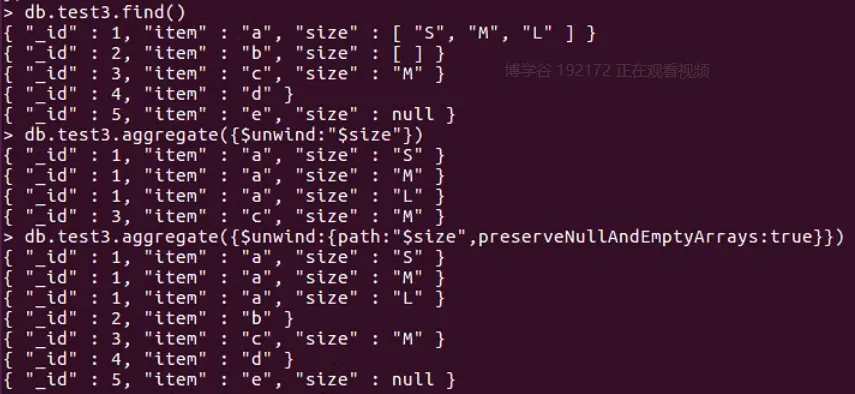
- 常见数据类型

- _id 主键
- 常见数据类型

- 索引
- 创建

- explain

- 删查
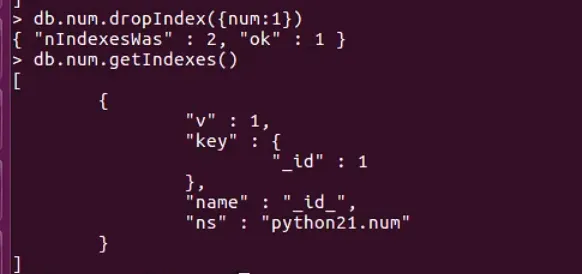
- 唯一索引

- 复合索引

- 权限管理
- auth 开启权限验证
- 创建超级管理员用户

- 创建普通用户

- 登录
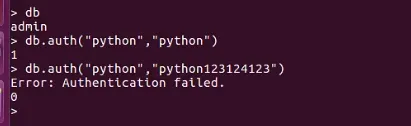
- db.getUsers() 查看用户
- db.dropUser() 删除用户
- 角色创建与数据库有关
- 可以在admin里统一创建,需要指定关联的数据库
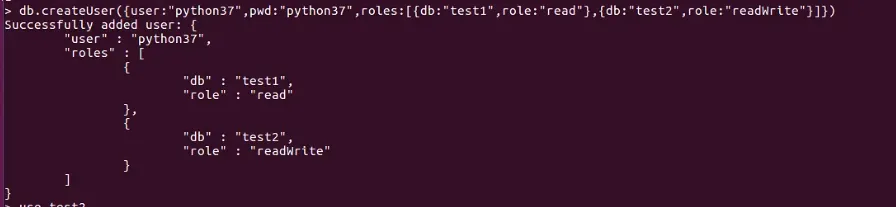
- 需要在admin里登录
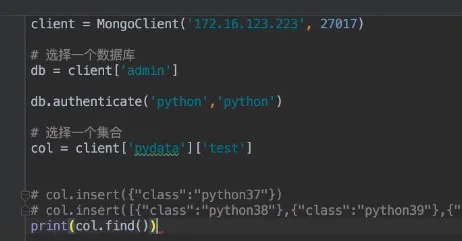
- python交互 pymongo


- Scrapy
- python爬虫框架
- 工作流程
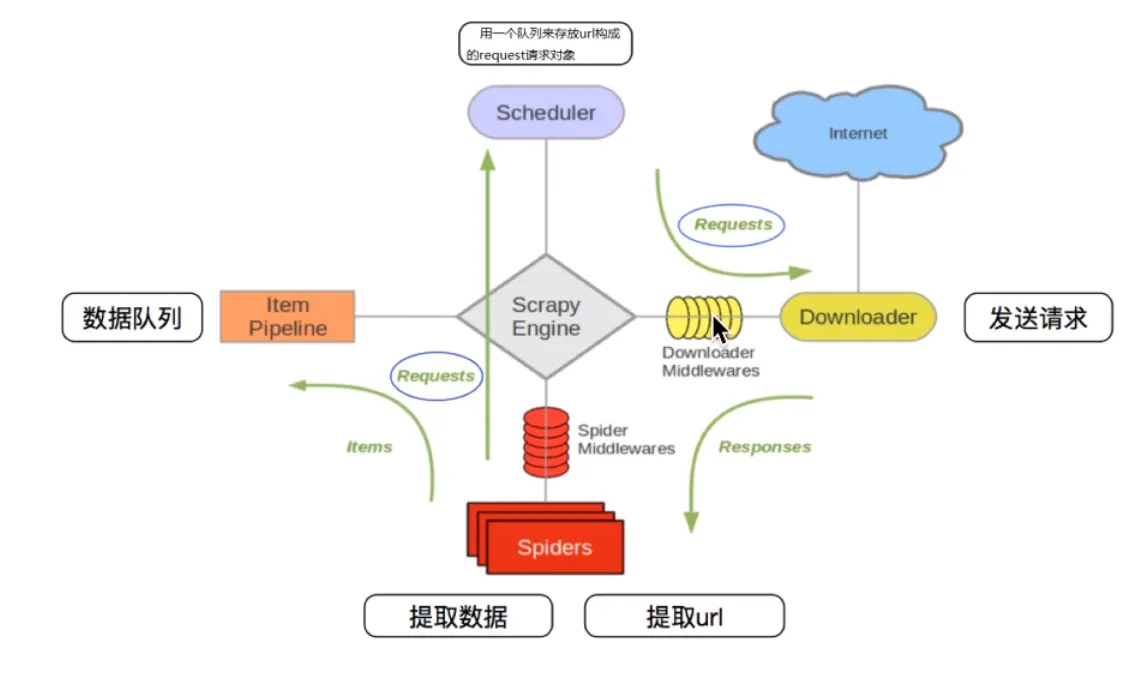
- 常用配置

- 各个模块作用
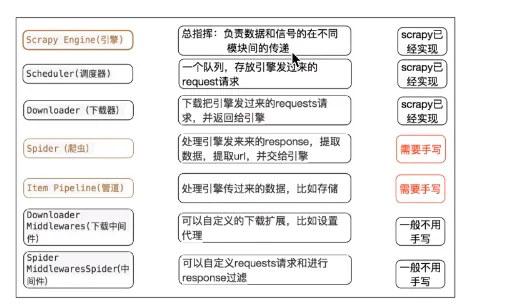
- 三个内置对象
- request
- response
- item
- 项目开发流程

- 开发流程
- 创建项目

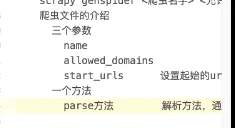
- 明确目标
- 数据建模 items.py中
- 为什么

- 创建爬虫
- scrapy genspider spider_name limit_domain
- 爬虫必须有parse方法
- 提取数据

- 保存数据
- 管道



- 定义管道
- 重写process_item方法
- 处理完item后返回给引擎
- 运行爬虫
- scrapy crawl spider_name
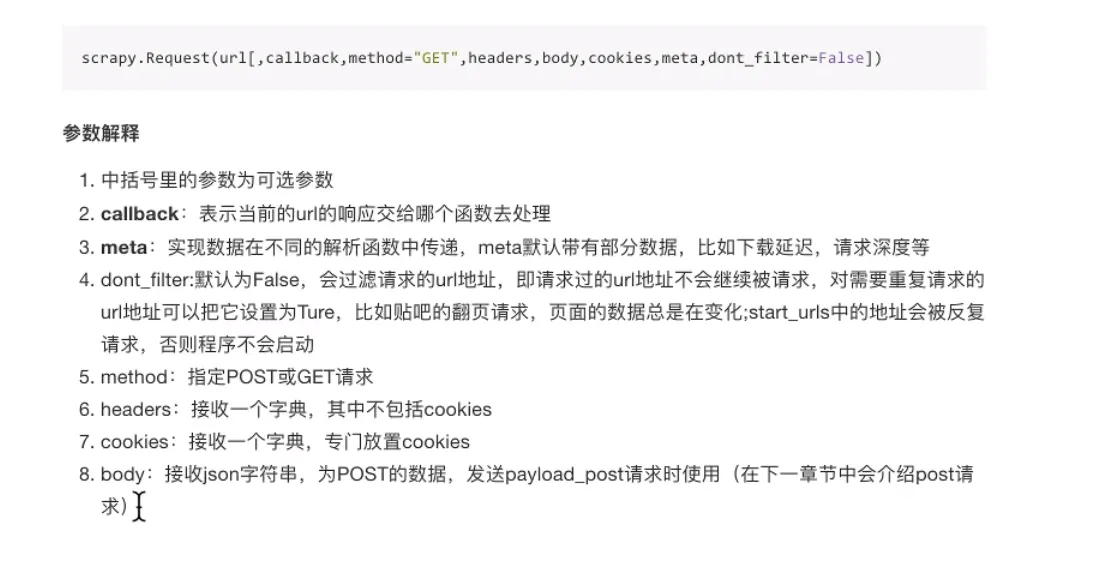
- 构造请求
- 参数
- 模拟登录
- 数据清洗

- crawlspider类
- 继承自Spider
- 创建 scrapy genspider -t crawl
- 创建类和链接提取规则
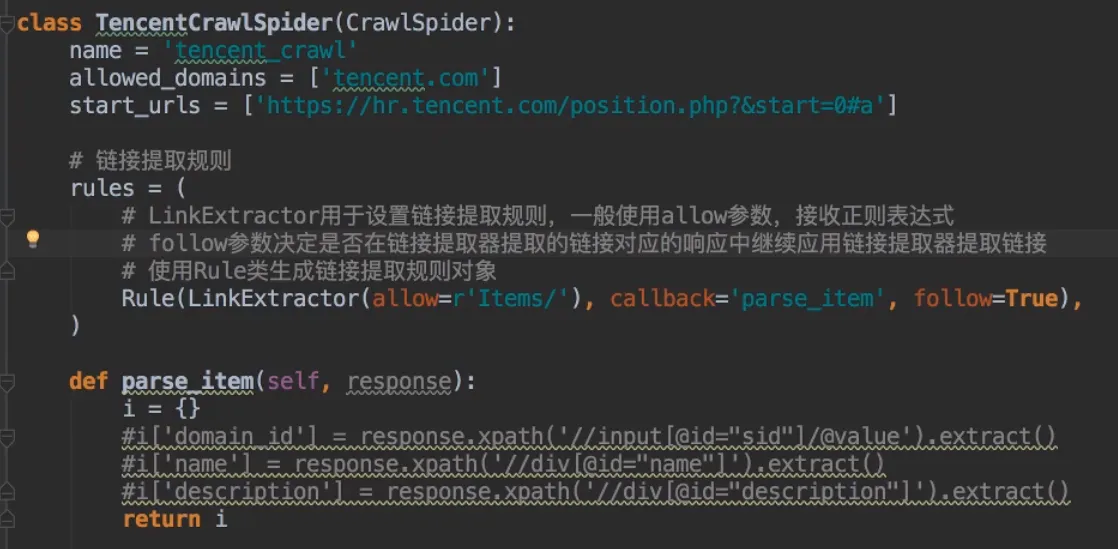
- 不能重写parse方法
- Shell
- scrapy shell url
- 中间件
- 分类
- 爬虫中间件
- 下载中间件

- Scrapy-Redis
- 分布式原理
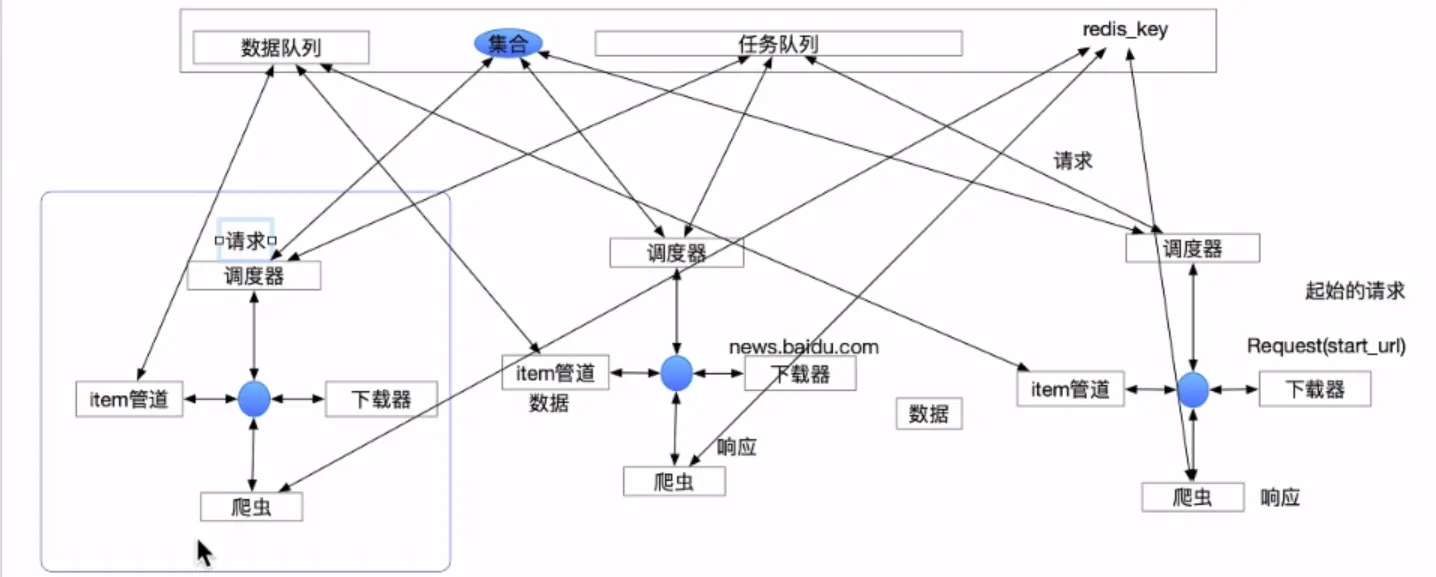
- 断点续爬
- 流程

- 区别

- 配置
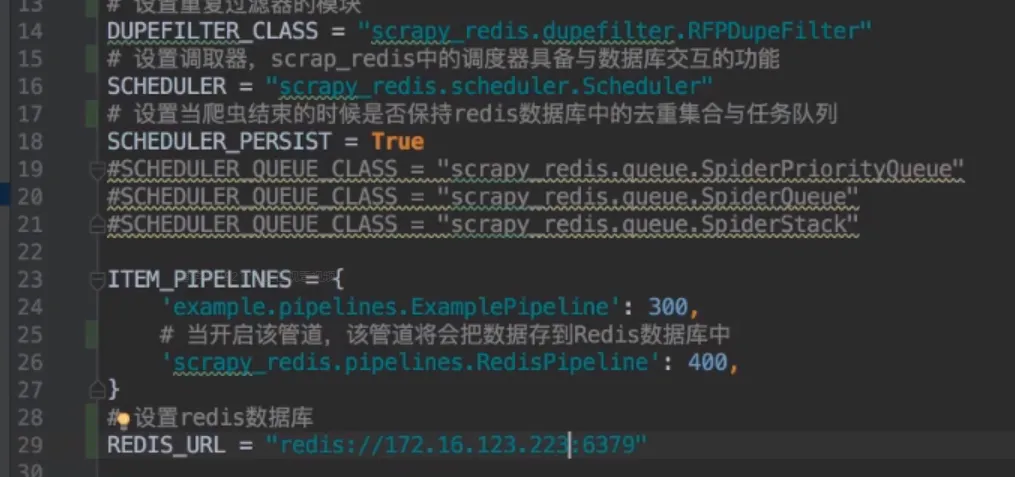
- 常用配置

- Scrapy-Splash
- 介绍

- 安装

- python模块安装
- pip install scrapy-splash、
- 配置
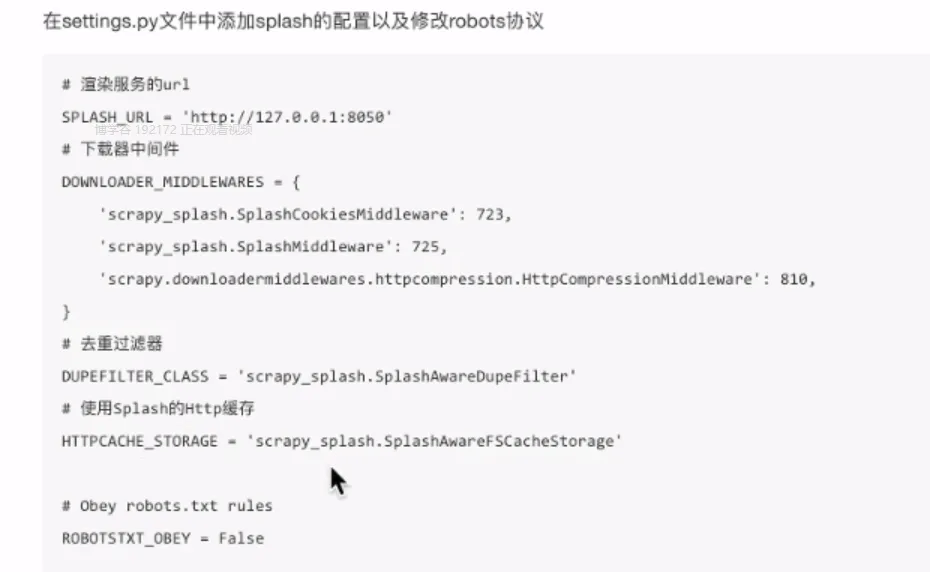
- 常用配置
- 使用

- Scrapyd
- 部署爬虫
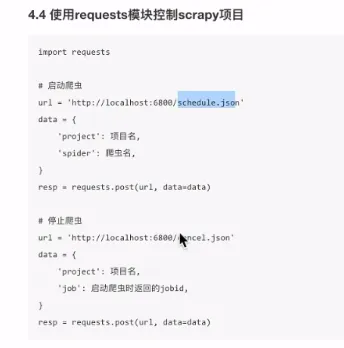
- 端口: 6800
- 安装
- 服务端
- pip install scrapyd
- 客户端
- pip install scrapyd-client
- 配置

- 管理
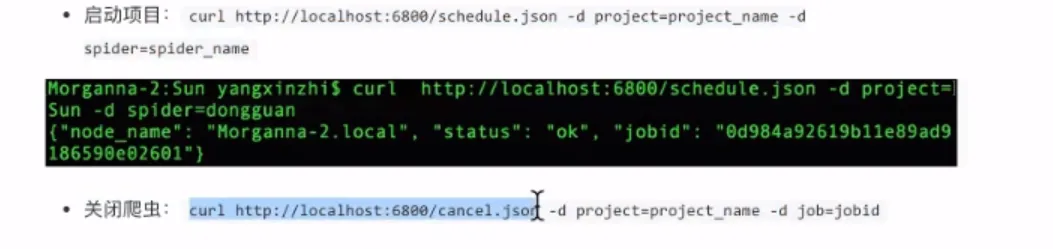
- 使用requests管理